Exploratory Data Analysis
1. 概述[1]
数据科学家使用探索性数据分析 (Exploratory Data Analysis) 来分析和调查数据集并总结其主要特征,通常采用数据可视化方法。它有助于确定如何最好地操纵数据源以获得所需的答案,从而使数据科学家更容易发现模式、发现异常、检验假设或检查假设。
EDA 主要用于查看在正式建模或假设检验任务之外可以揭示哪些数据,并提供对数据集变量及其之间关系的更好理解。它还可以帮助确定您正在考虑用于数据分析的统计技术是否合适。
EDA 技术最初由美国数学家 John Tukey 在 1970 年代开发,在今天的数据发现过程中仍然是一种广泛使用的方法。
EDA 的主要目的是帮助在做出任何假设之前查看数据。它可以帮助识别明显的错误,更好地理解数据中的模式,检测异常值或异常事件,找到变量之间的有趣关系。
EDA 是任何数据分析中重要的第一步。了解异常值出现的位置以及变量之间的关系有助于设计能够产生有意义结果的统计分析。
数据科学家可以使用探索性分析来确保他们产生的结果是有效的并且适用于任何期望的业务成果和目标。EDA 还通过确认他们提出正确的问题来帮助利益相关者。EDA 可以帮助回答有关标准差、分类变量和置信区间的问题。一旦 EDA 完成并得出见解,它的功能就可以用于更复杂的数据分析或建模,包括机器学习。
2. 数据总览
本文实例数据使用 kaggle 的 Spaceship Titanic 数据集。
训练数据共有如下字段
- PassengerId - A unique Id for each passenger. Each Id takes the form gggg_pp where gggg indicates a group the passenger is travelling with and pp is their number within the group. People in a group are often family members, but not always.
- HomePlanet - The planet the passenger departed from, typically their planet of permanent residence.
- CryoSleep - Indicates whether the passenger elected to be put into suspended animation for the duration of the voyage. Passengers in cryosleep are confined to their cabins.
- Cabin - The cabin number where the passenger is staying. Takes the form deck/num/side, where side can be either P for Port or S for Starboard.
- Destination - The planet the passenger will be debarking to.
- Age - The age of the passenger.
- VIP - Whether the passenger has paid for special VIP service during the voyage.
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck - Amount the passenger has billed at each of the Spaceship Titanic’s many luxury amenities.
- Name - The first and last names of the passenger.
- Transported - Whether the passenger was transported to another dimension. This is the target, the column you are trying to predict.
数据都是虚拟的,主要目的是预测 Transported,是否被送到了异次元。
首先导入数据
import pandas as pd
train_data = pd.read_csv('Data/train.csv')
test_data = pd.read_csv('Data/test.csv')
然后获取数据简明摘要,包括索引 dtype 、列名、非空值和内存使用情况。
train_data.info()
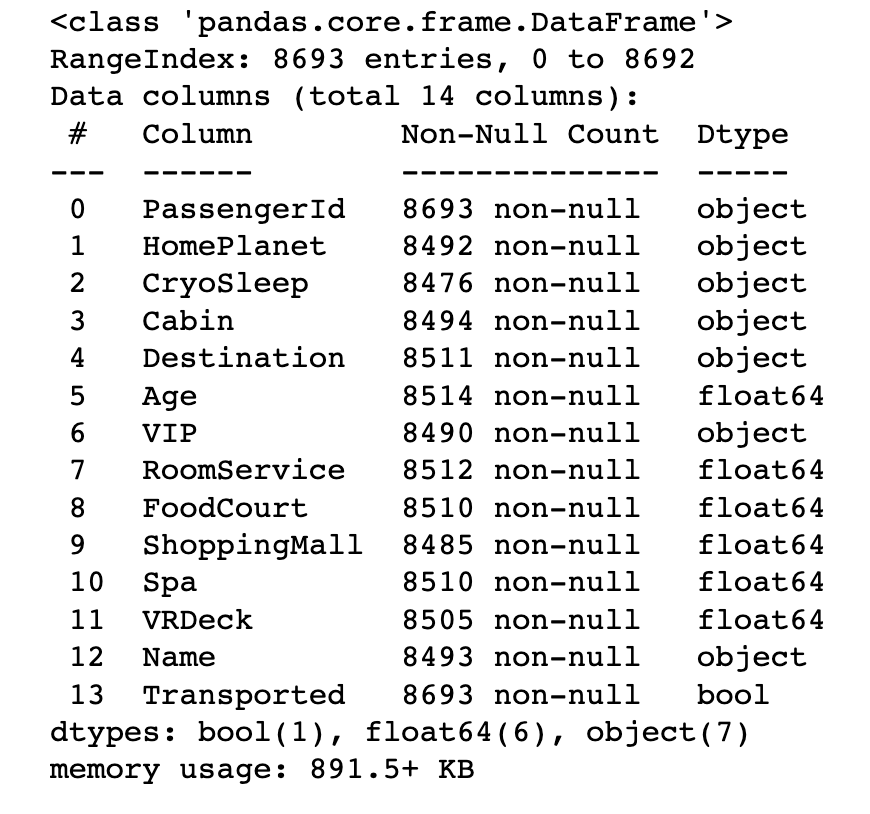
可以看出来大部分字段缺失几乎200条数据,同时存在字符和数字型的数据。
然后生成描述性统计,包括数据集分布的集中趋势、离散度和形状的统计数据,不包括 NaN 的值,即不包括缺失值。
train_data.describe()
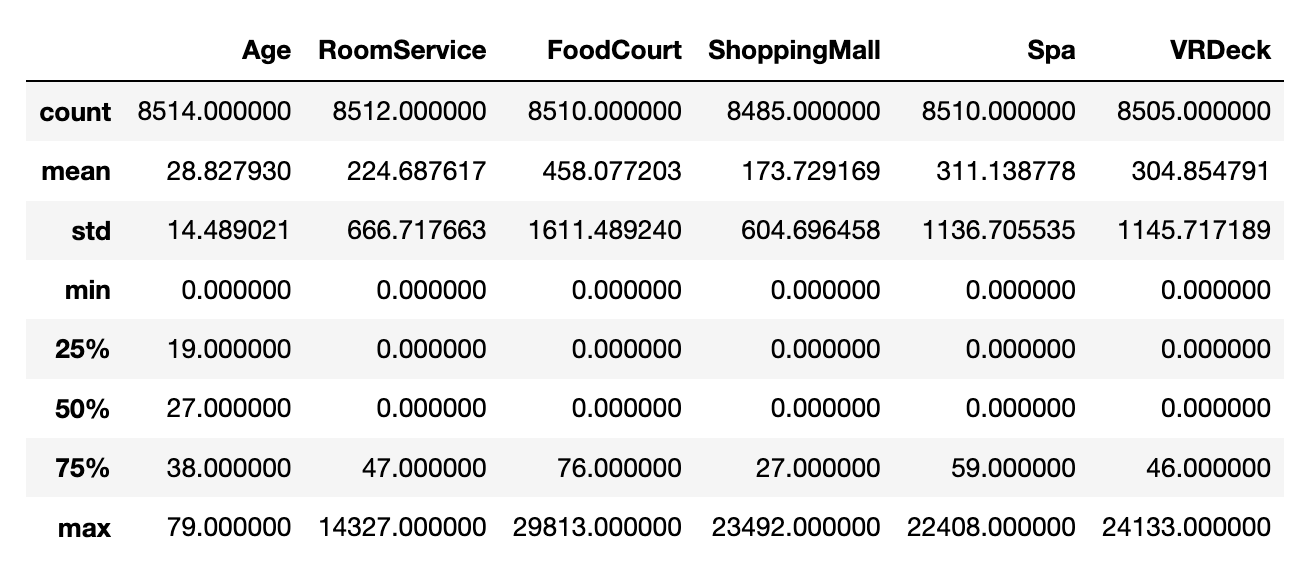
% 指的是百分位数,50% 即为中位数。
由于字符型和布尔型数据还没有数字化,因此只统计了年龄和和各项消费情况,可以看出消费情况的方差非常大,可见贫富差距很明显。
最后查看前五条数据
train_data.head()
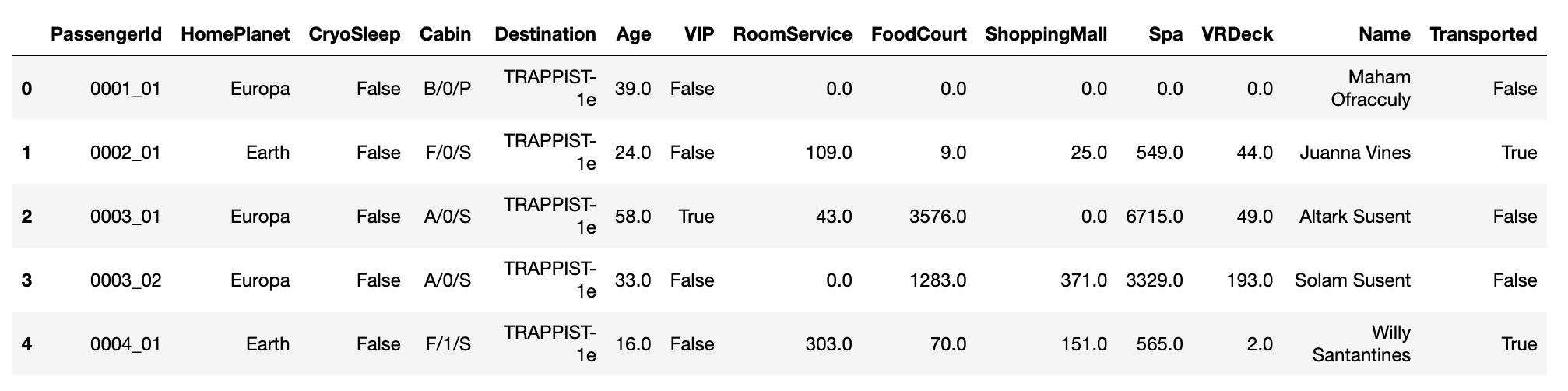
3. 数据拆分
PassengerId 和 Cabin 中包含了多个信息,PassengerId 中有 group 和个人的编号,而 Cabin 中有客舱编号与位置,因此需要进行拆分。
可以使用 pandas 内置函数 pandas.Series.str.split
combine_data = [train_data, test_data]
for df in combine_data:
df[['Deck', 'Num', 'Side']] = df['Cabin'].str.split('/', expand = True)
df[['PGroup','PNr']] = df['PassengerId'].str.split('_', expand=True)
df['Num'] = df['Num'].astype('float')
df['PNr'] = df['PNr'].astype('float')
df['PGroup'] = df['PGroup'].astype('float')
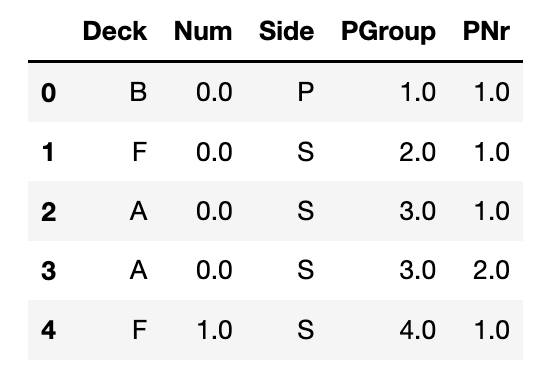
train_data[['Deck', 'Num', 'Side', 'PGroup','PNr']].head()
expand 选择是否将拆分的字符串展开为单独的列,如果 False 的话则返回一个字符串列表。
astype 指定 series 的数据类型,将 str 转换为 float。
拆分后的结果如下
4. 数据可视化
数据分为连续数据和分类数据,无论哪种数据,都可以通过各种图形了解其自身分布情况以及与其他变量之间的相关关系等等。
seaborn 库是对 matplotlib 进行封装而成的,功能强大并且操作简单,完美契合 pandas 数据结构。
导入 seaborn 库,并且设置默认参数,这样就不用每次设置 figure 的dpi,同时设置一个好看的主题。
import seaborn as sns
plt.rcParams['figure.dpi'] = 240
sns.set_theme(style="darkgrid")
4.1 直方图
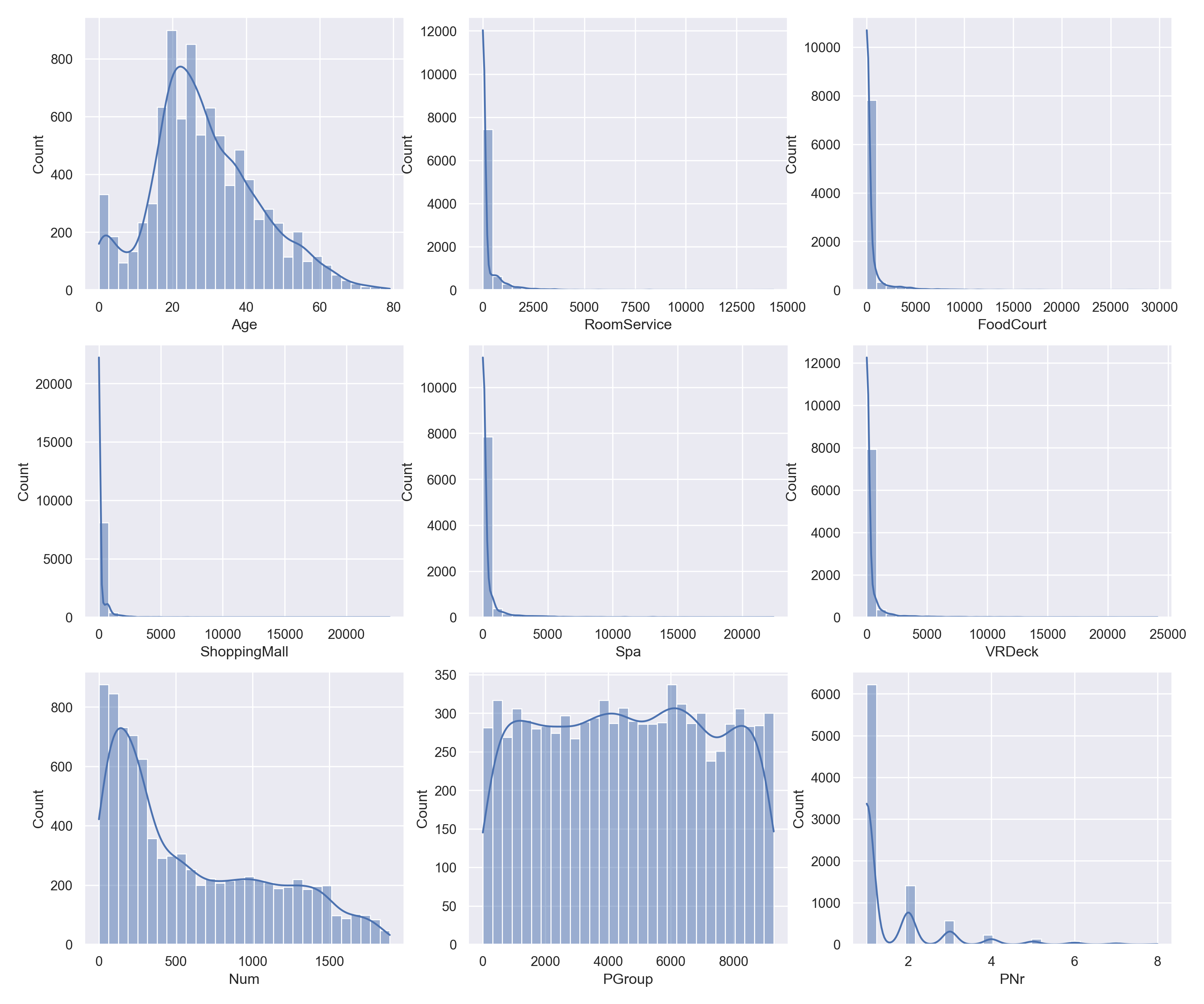
直方图是经典的可视化工具,它通过计算落在离散区间内的观察数来表示一个或多个变量的分布。
首先看一下 Age 的分布情况。
plt.title("Age in counts")
sns.histplot(data=train_data, x="Age")
plt.savefig('img/5.png')
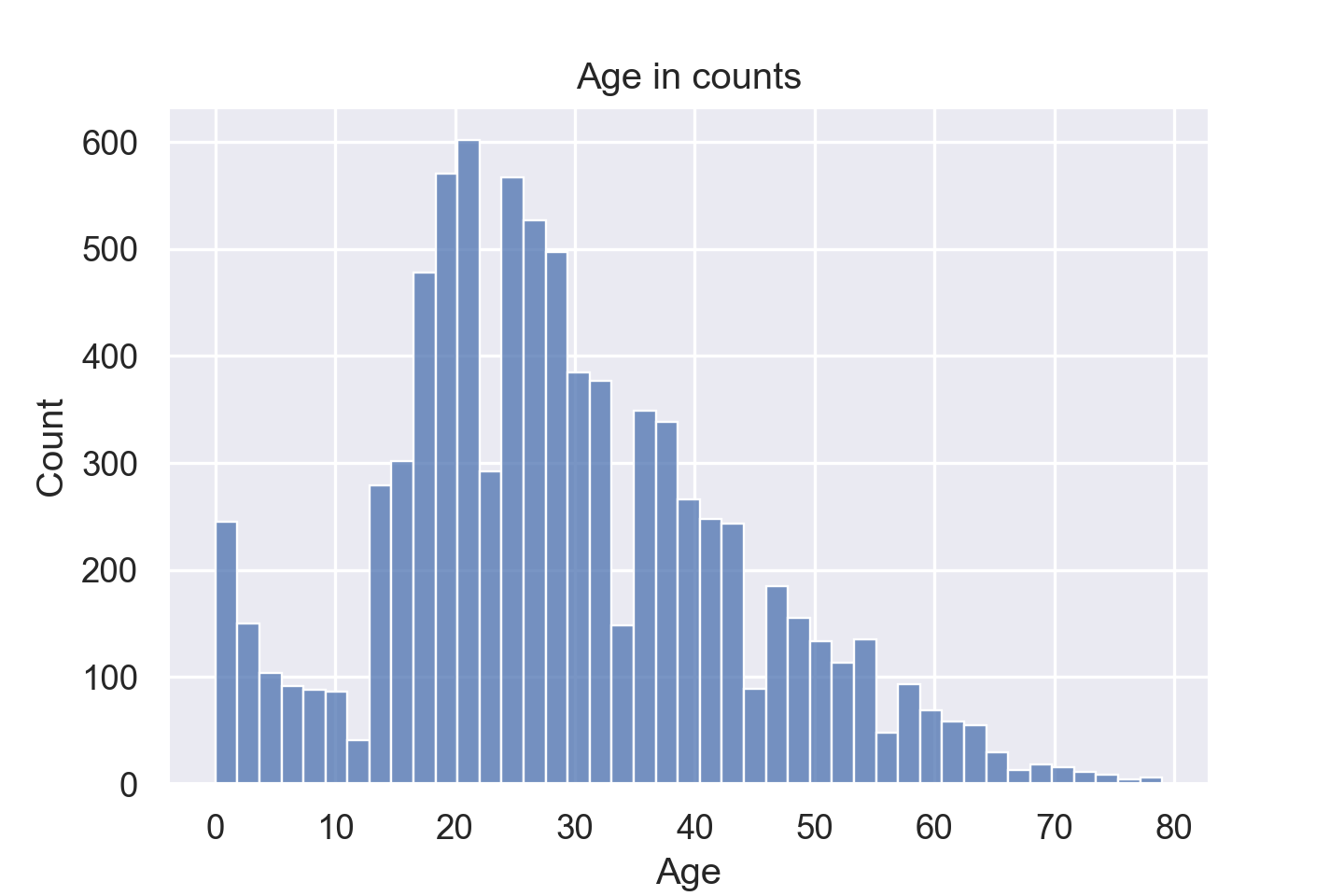
可以看出比较符合正态分布,但是由于 bin 值设置过小,导致中间会有缺失值。通过 binwidth 设置区间的宽度,或者 bins 设置总的划分区间,我们采取第一种方式。
sns.histplot(data=train_data, x="Age", binwidth=5)
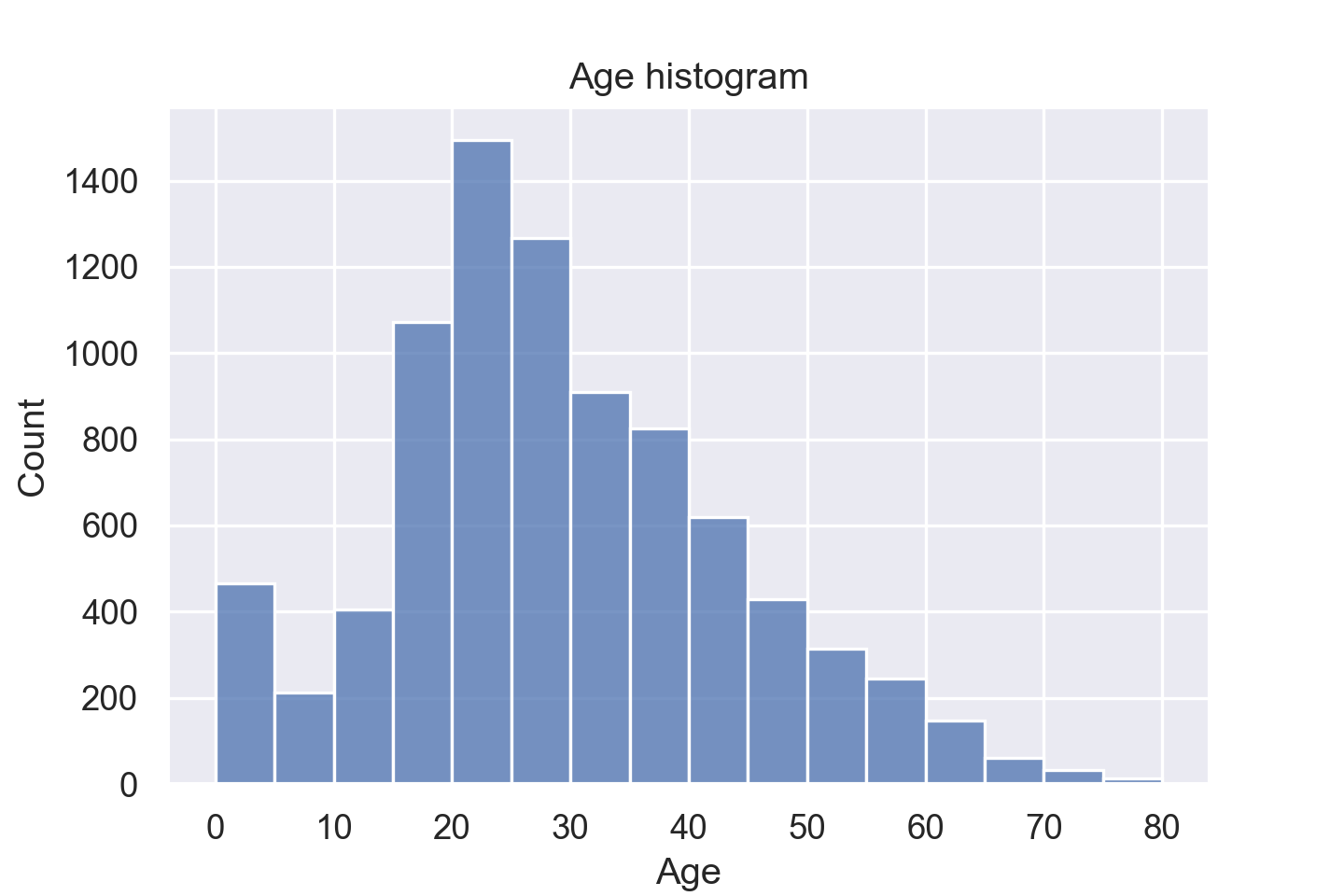
bin 值改进之后可以发现分布更趋于正态了。
小孩异常多,本来以为是把缺失值当成 0 处理了,但实际并不是,seaborn 是把缺失值忽略了。Age 为 0 的数据本身就有 175 条,有些不合理。
可以同时在图中加入核密度[2]估计来平滑直方图。默认使用的是高斯核。
计算公式为
sns.histplot(data=train_data, x="Age", binwidth=5, kde=True)
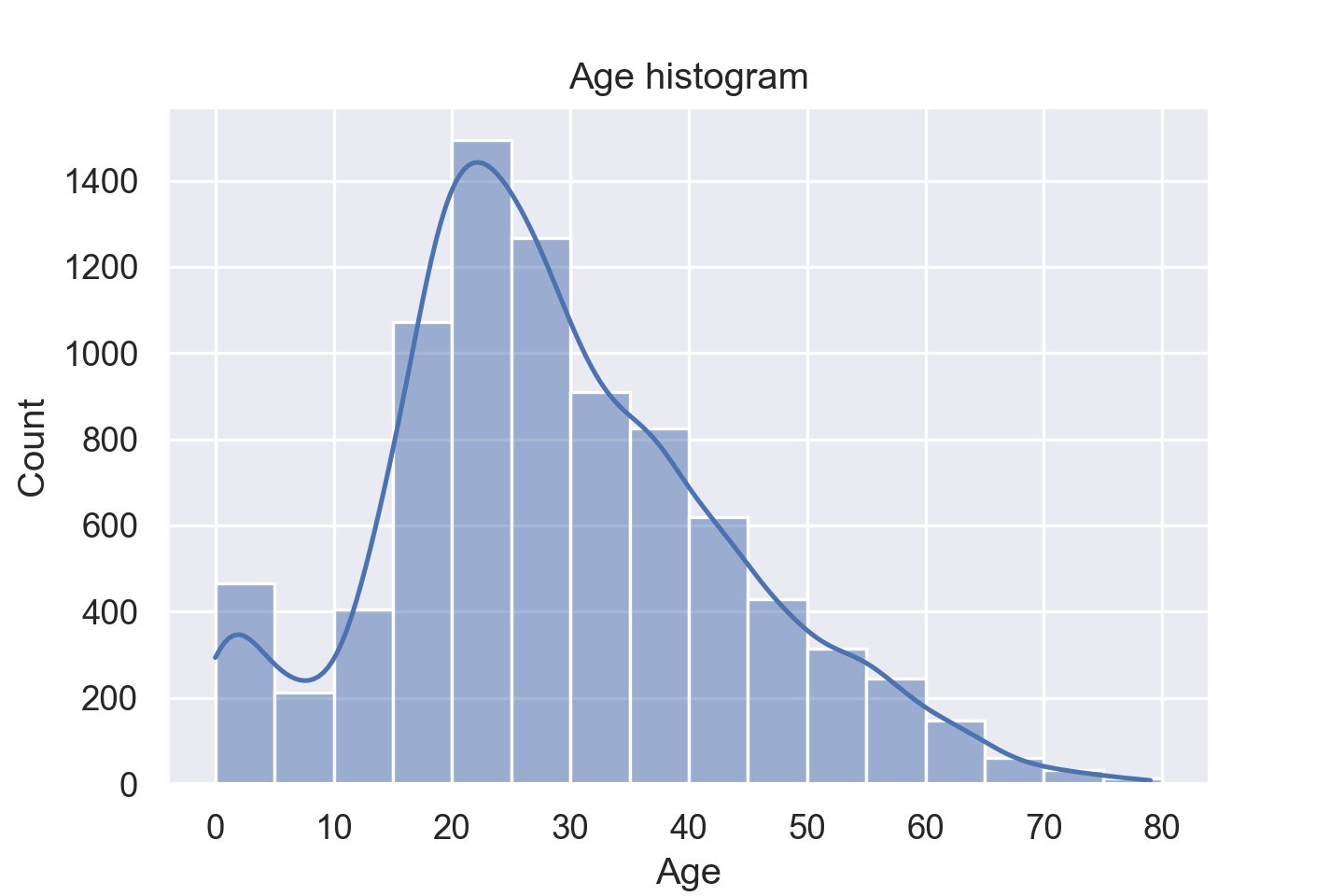
从拟合的核密度函数来看,似乎更像是正偏态分布。
计算一下偏度值
train_data["Age"].skew()
结果为 0.419,确实有一定程度正偏。
接下来再看一下有关消费金额的直方图。
sns.histplot(data=train_data, x="FoodCourt", bins=30)
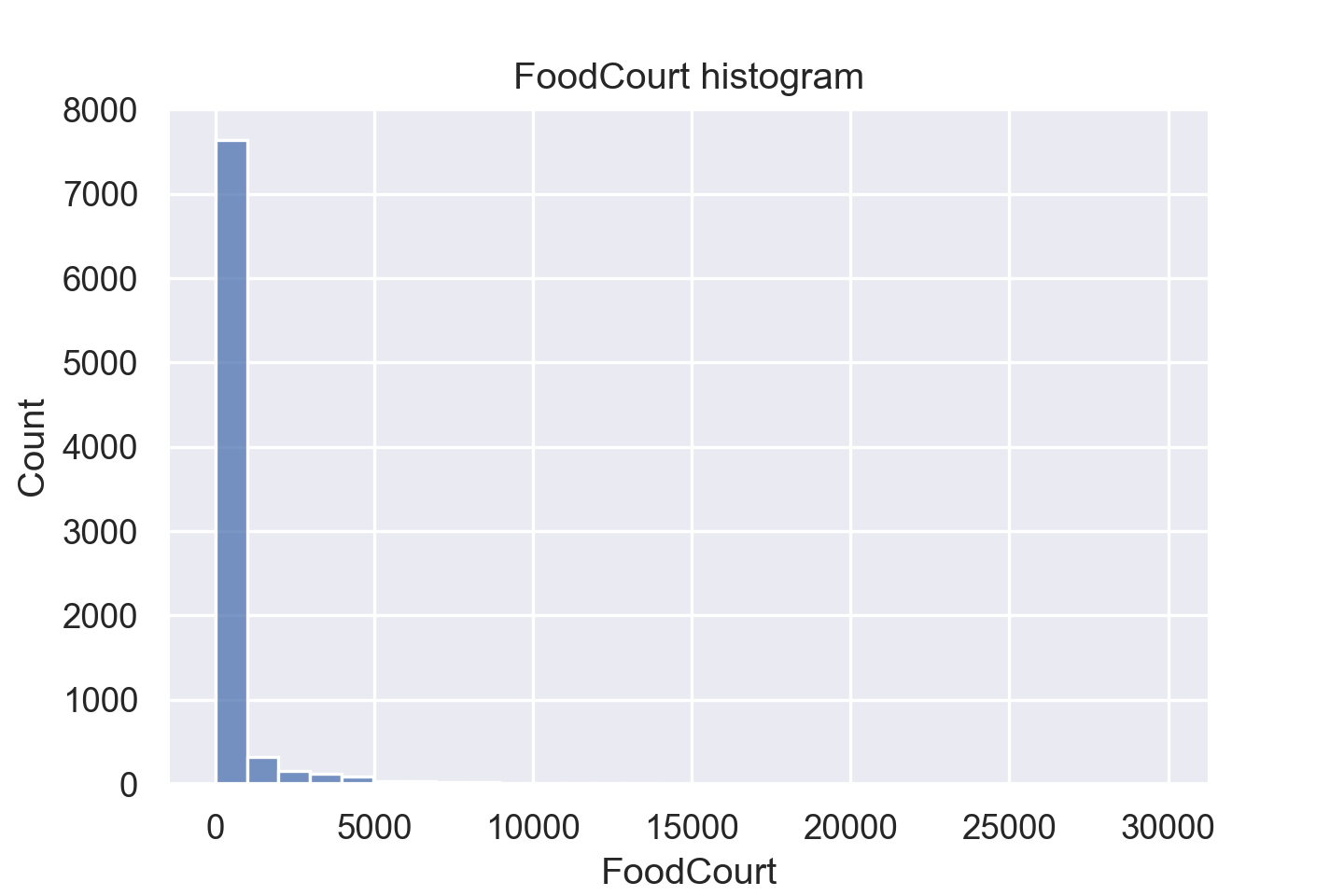
可以看出来数据偏斜非常严重,后面的数据几乎显示不出来,这时可以对数值进行取对数,将其映射到 log 空间。
plt.title("FoodCourt histogram")
tmp_df = train_data[["FoodCourt"]] + 1
sns.histplot(data=tmp_df, x="FoodCourt", bins=30, log_scale=True)
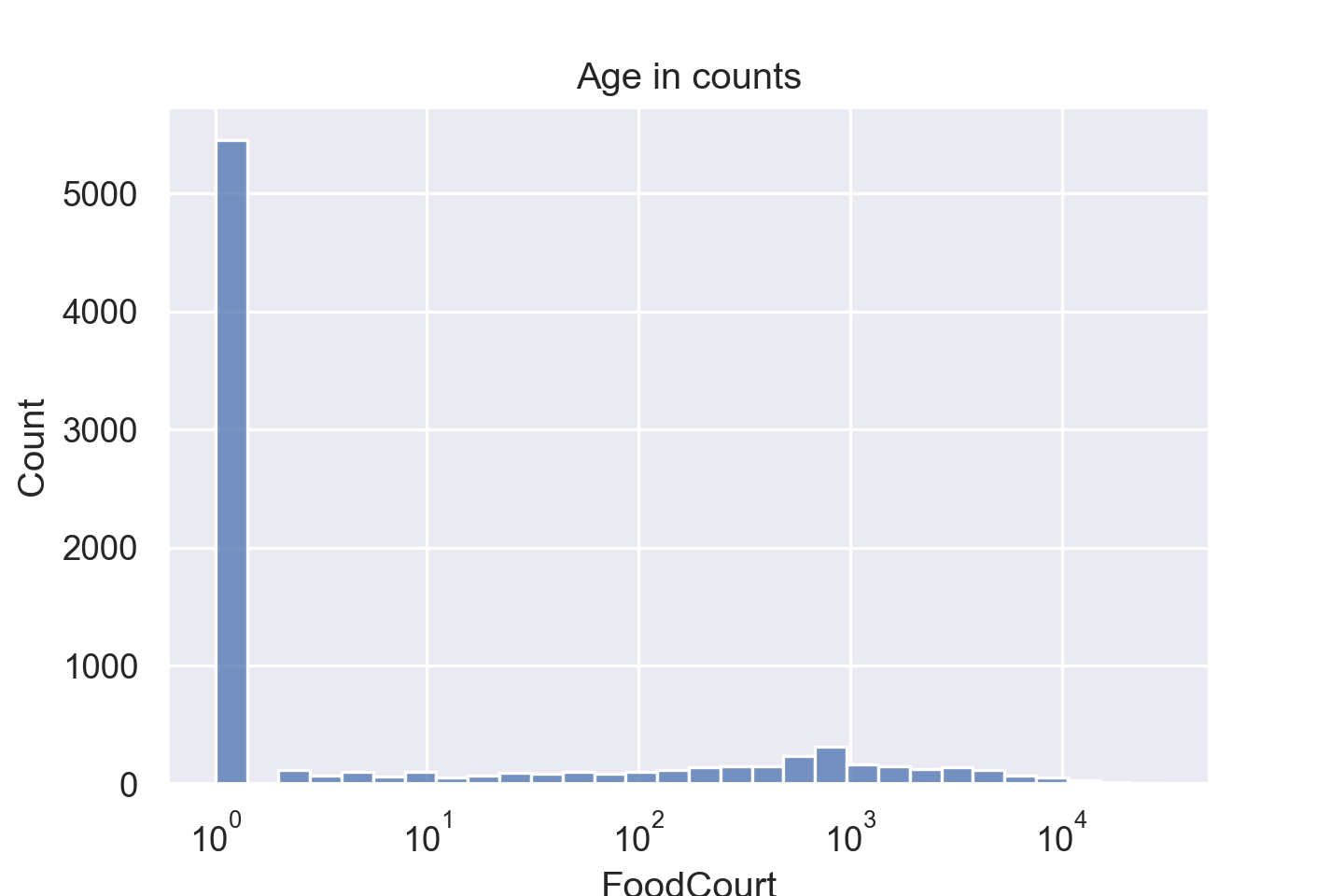
由于取对数时值不能为 0,因此需要将所有值 +1。
从图中差不多可以看出数据的分布情况了,但还是会有偏斜,因此我们直接剔除值为0的数据,然后再看一下分布情况。
sns.histplot(data=train_data[train_data["FoodCourt"]!=0], x="FoodCourt", bins=30, log_scale=True)
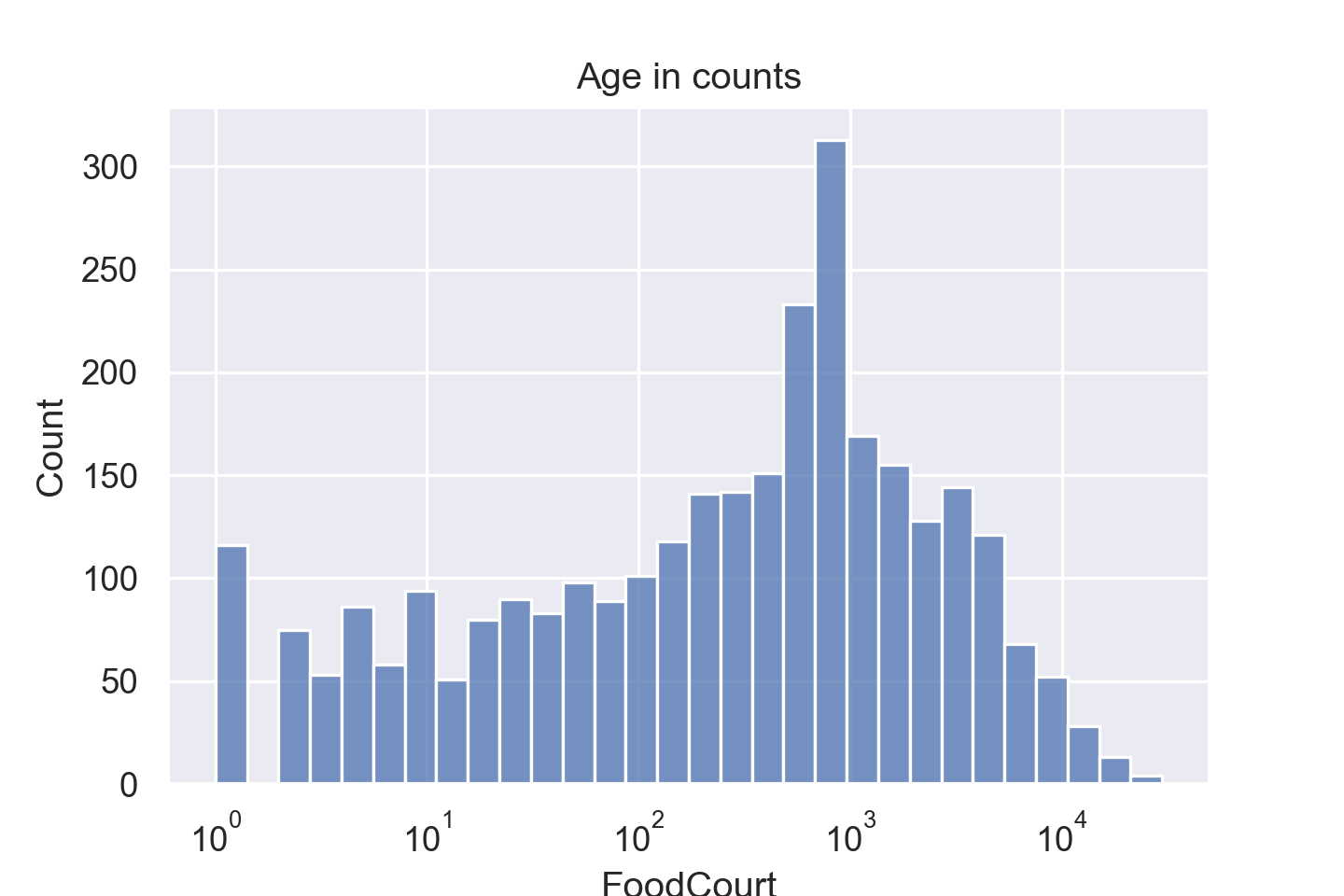
差不多满足正态分布了,对于这种数据严重偏斜的,后面数据预处理的时候就需要进行取对数。
histplot 也支持色调映射,通过颜色来反映其他数据的分布情况,例如
sns.histplot(data=train_data, x="Num", hue='Transported')
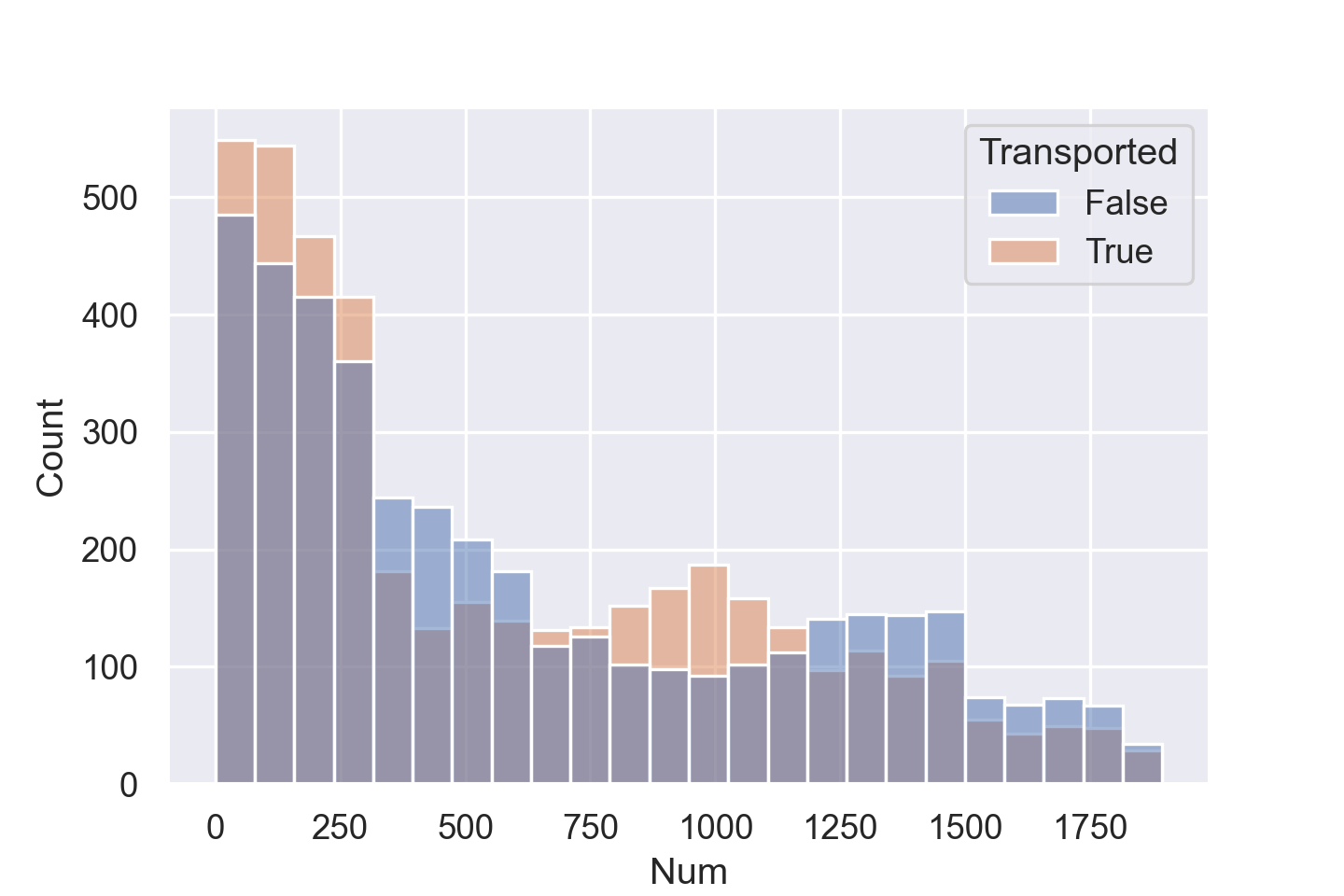
可以看出来编号的初段和中段被送往异次元的人数更多。
最后对所有连续数值型的特征进行直方图汇总。
columns=['Age', 'Num', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
row, col = divmod(len(columns), 3)
fig, ax = plt.subplots(row + 1, 3, figsize=(16,14))
for idx, column in enumerate(columns):
row, col = divmod(idx, 3)
if column in ['Age', 'Num']:
sns.histplot(data=train_data, x=column, hue='Transported', ax=ax[row, col], kde=True, bins=30)
else:
tmp_df = train_data[[column]] + 1
tmp_df['Transported'] = train_data['Transported']
sns.histplot(data=tmp_df, x=column, hue='Transported', ax=ax[row, col], log_scale=True, kde=True, bins=30)
plt.savefig('img/12.png', bbox_inches='tight', pad_inches = 0.5) #调整margins
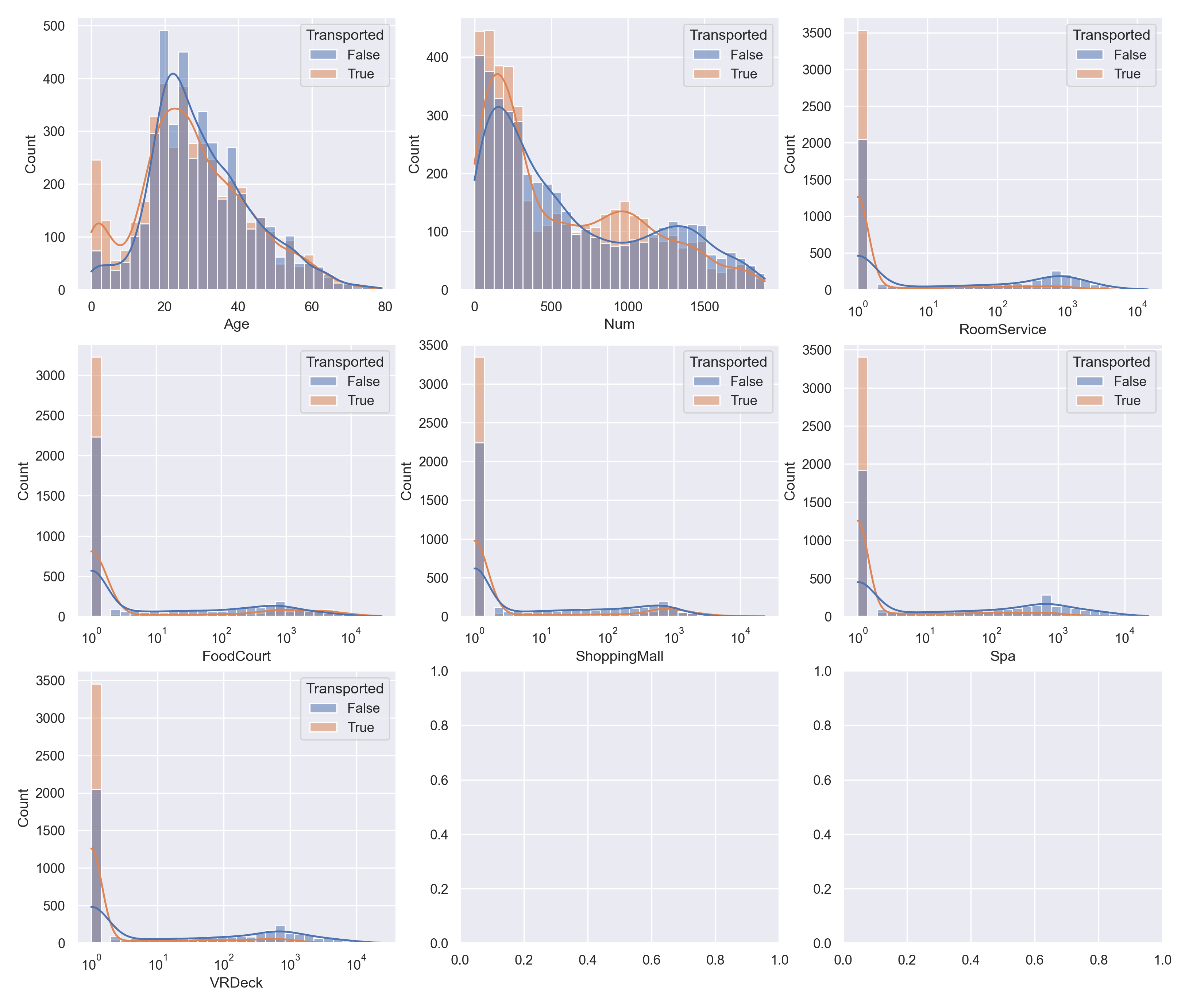
4.2 计数图
计数图实际上是应用于分类变量而不是连续变量的直方图,目的是对分类变量的分布情况进行可视化。
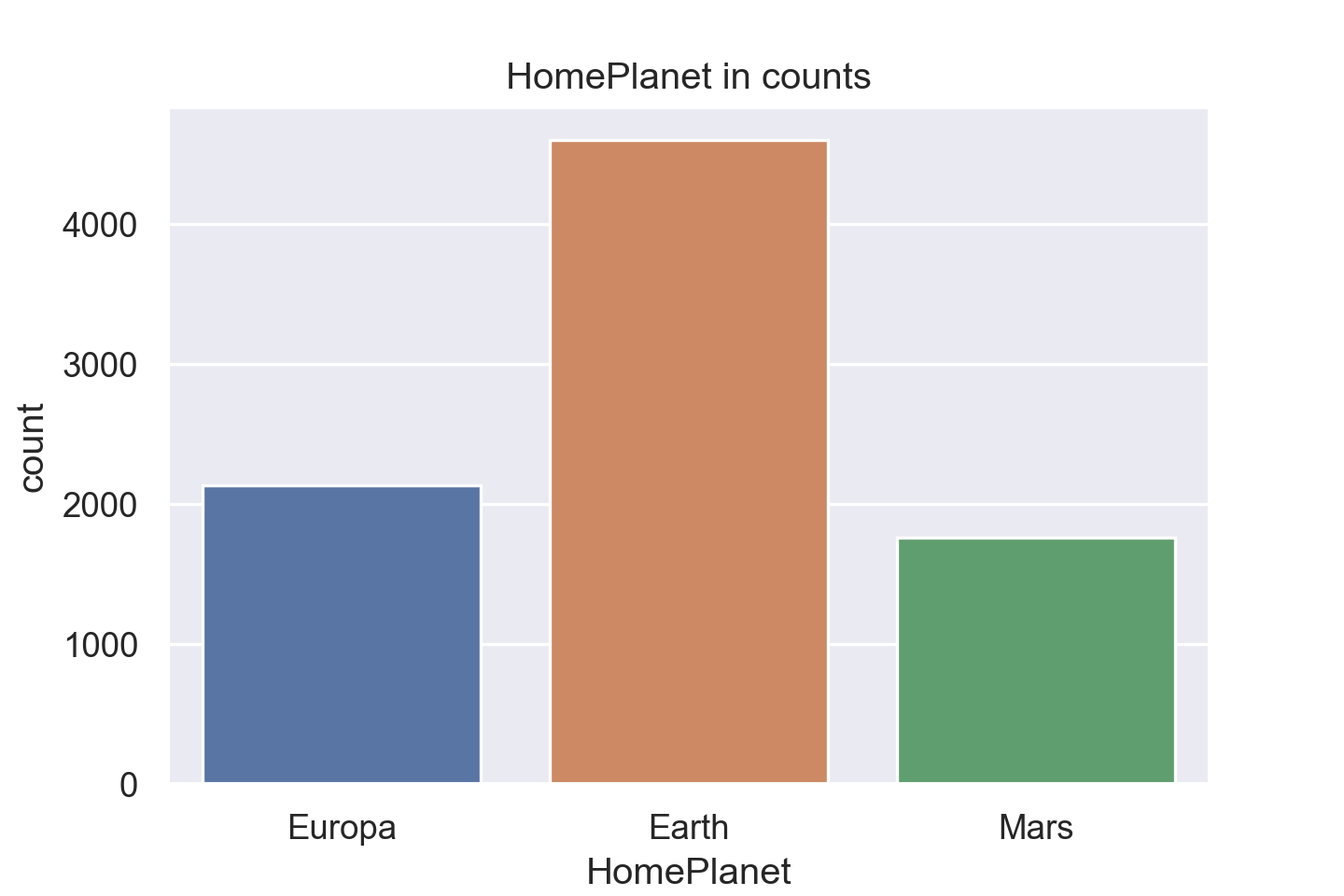
plt.title("HomePlanet in counts")
sns.countplot(data=train_data, x="HomePlanet")
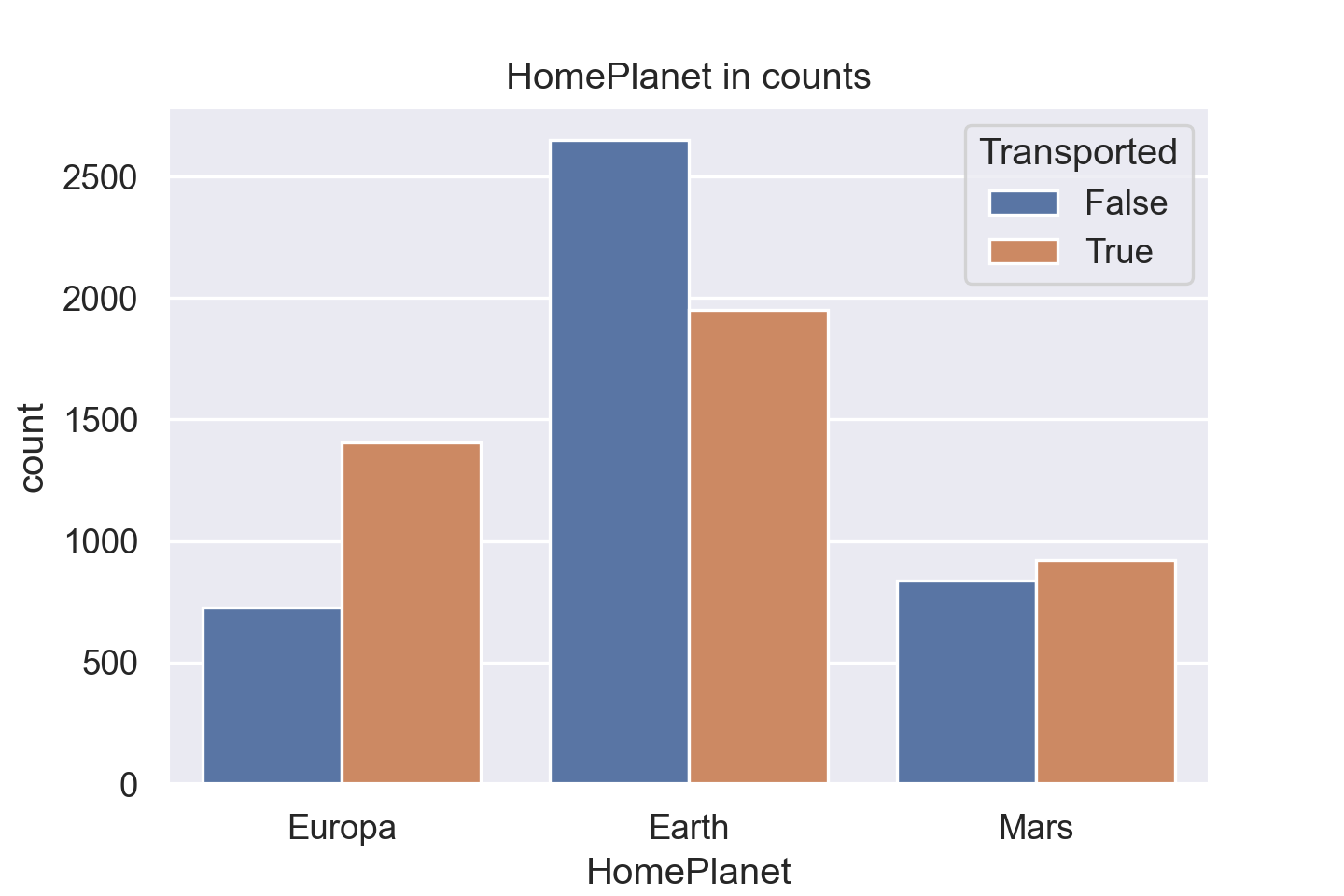
类似于上面的 histplot,可以通过设置 hue 来引入第二个变量。
plt.title("HomePlanet in counts")
sns.countplot(data=train_data, x="HomePlanet", hue="Transported")
我们对所有分类变量进行计数图汇总。
columns=['HomePlanet', 'CryoSleep', 'Destination', 'VIP', 'Deck', 'Side']
row, col = divmod(len(columns), 3)
fig, ax = plt.subplots(row, 3, figsize=(16,7))
for idx, column in enumerate(columns):
row, col = divmod(idx, 3)
sns.countplot(data=train_data, x=column, hue='Transported', ax=ax[row, col])
plt.savefig('img/15.png', bbox_inches='tight', pad_inches = 0.2)
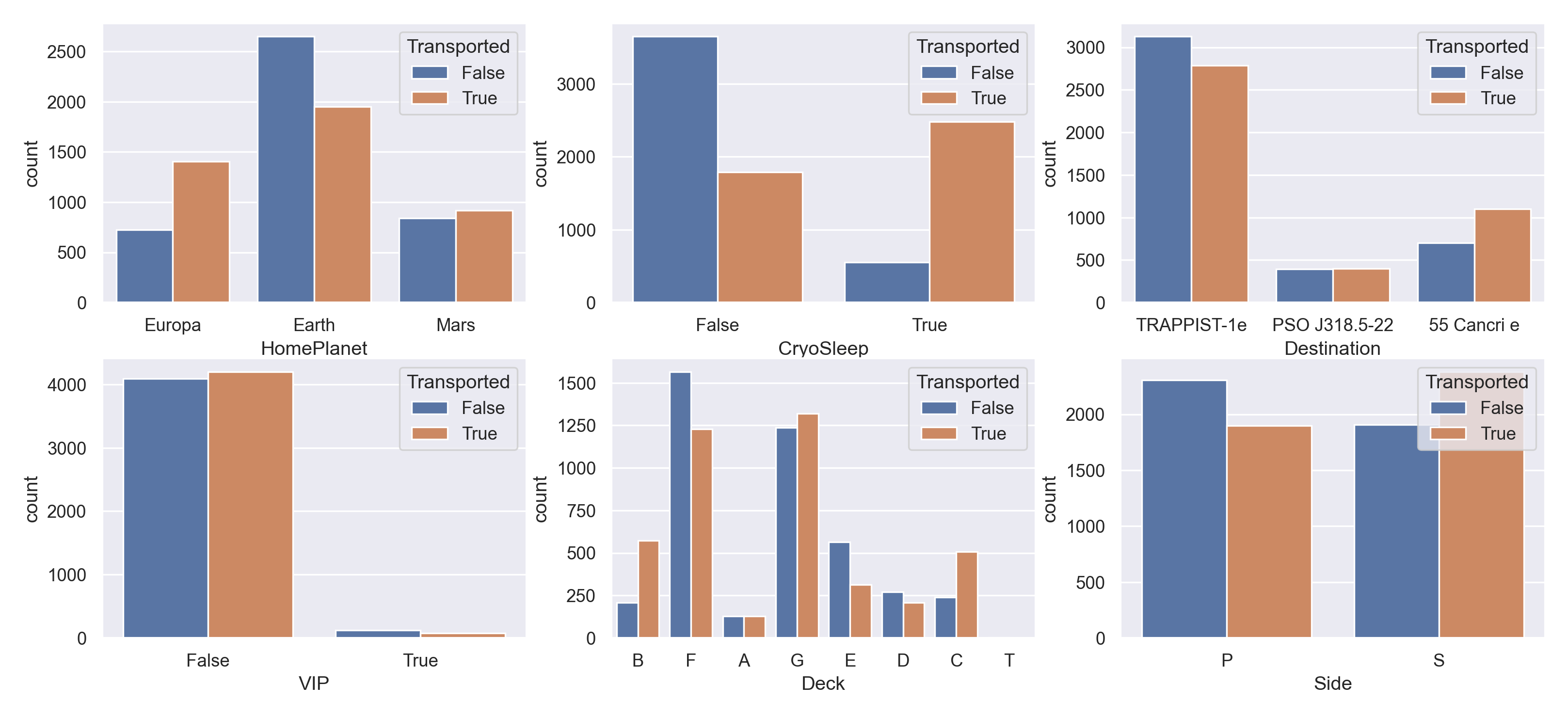
可以看出不同分类变量与预测值之间相关性最大的是 cryoSleep,睡眠的人大概率进入了异次元。
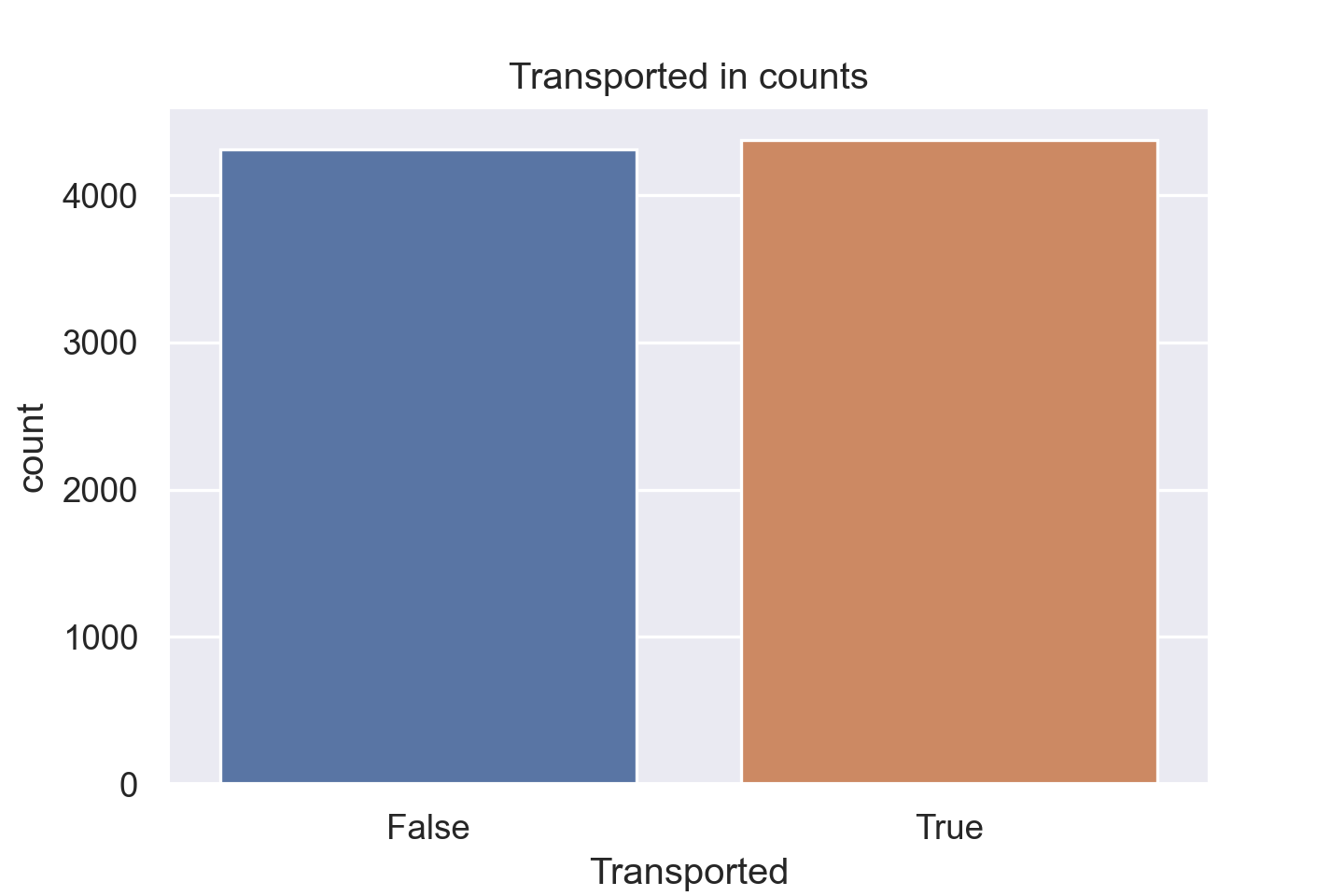
最后看一眼 Transported 的分布情况。
plt.title("Transported in counts")
sns.countplot(data=train_data, x="Transported")
4.3 箱线图
箱线图(Boxplot) 也称箱须图(Box-whisker Plot),它是用一组数据中的最小值、第一四分位数、中位数、第三四分位数和最大值来反映数据分布的中心位置和散布范围,可以粗略地看出数据是否具有对称性,分布的离散程度等信息;如果将多组数据的箱线图画在同一坐标上,则可以清晰地显示出各组数据的分布差异,为发现问题、改进问题提供支持。
通过分位数之间的距离可以计算出数据的上下限,超出上下限的数据称为离群点,通常用叉号或别的符号标注在数轴上。
plt.title("Age Box Plot")
sns.boxplot(data=train_data, x="Age")
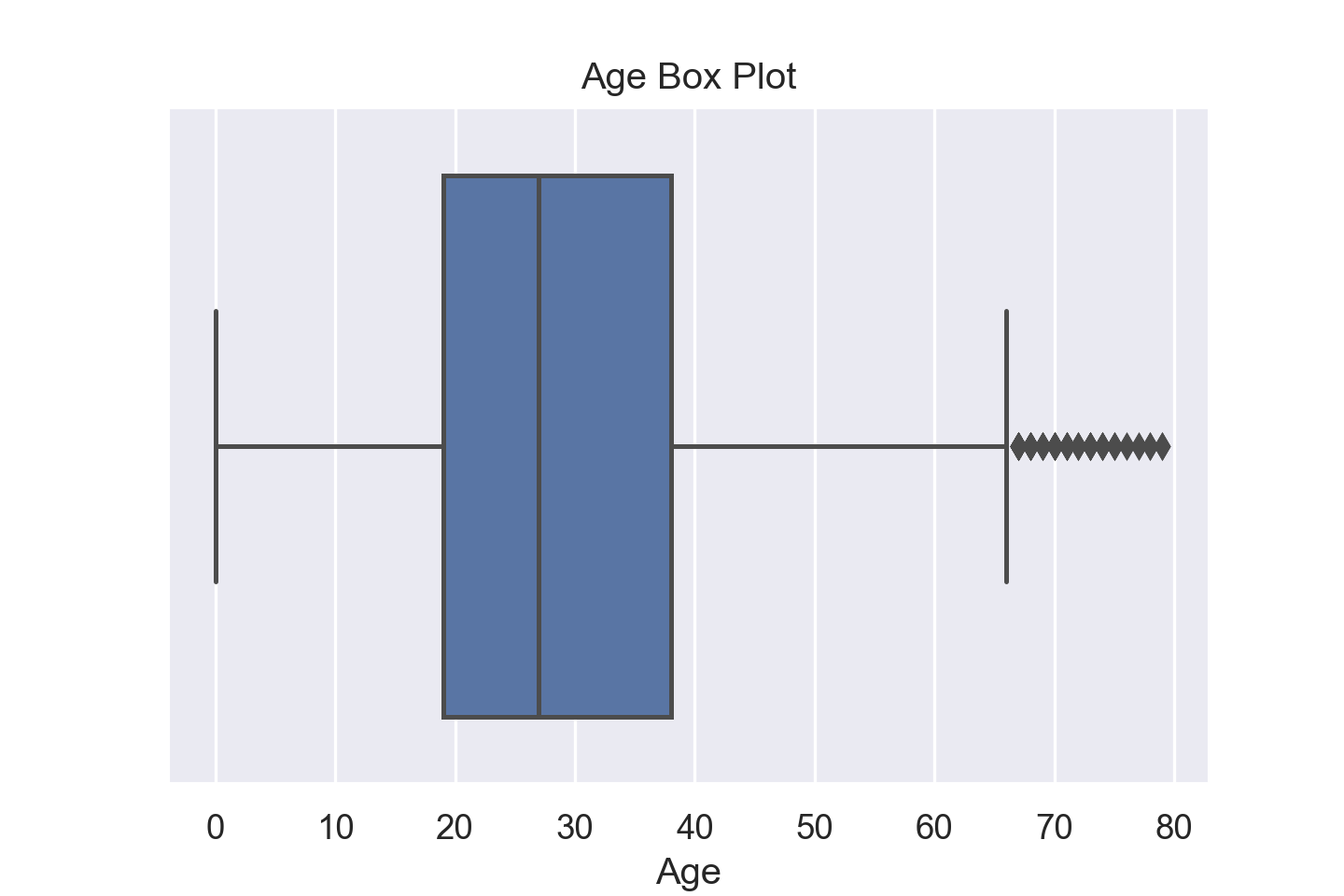
我们对所有连续变量进行箱线图汇总。
columns=['Age', 'Num', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
row, col = divmod(len(columns), 3)
fig, ax = plt.subplots(row + 1, 3, figsize=(16,7))
for idx, column in enumerate(columns):
row, col = divmod(idx, 3)
sns.boxplot(data=train_data, x=column, ax=ax[row, col])
plt.savefig('img/18.png', bbox_inches='tight', pad_inches = 0.2)
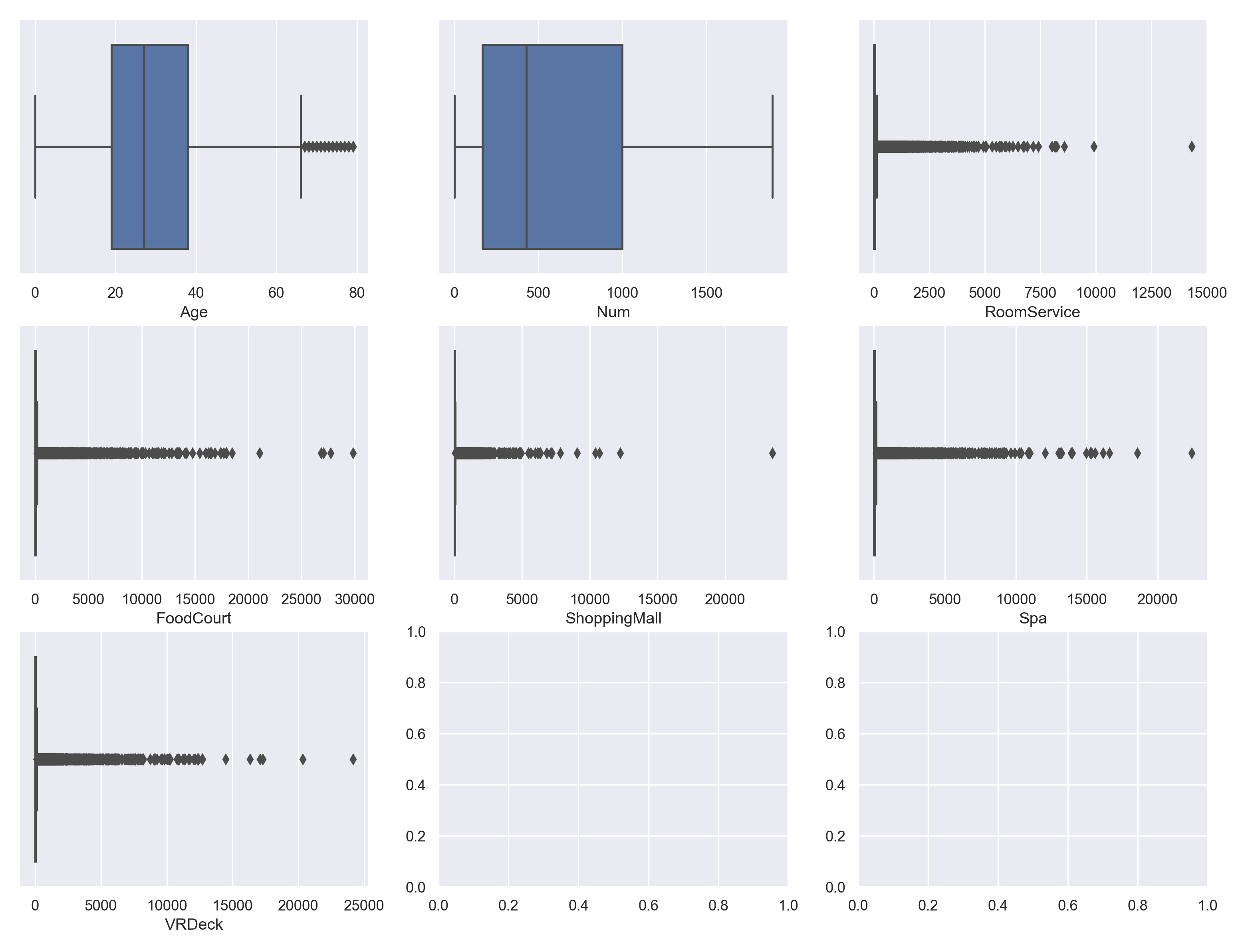
可以看出来几项金额的离群点非常多,这也表示需要对数据进行处理。
4.4 散点图
散点图主要用来判断两变量之间是否存在相关关系或者关联趋势,并且可以看出是线性或者非线性。对于离群值,通过散点图也可以做到一目了然。
sns.scatterplot(data=train_data, x="RoomService", y="FoodCourt")
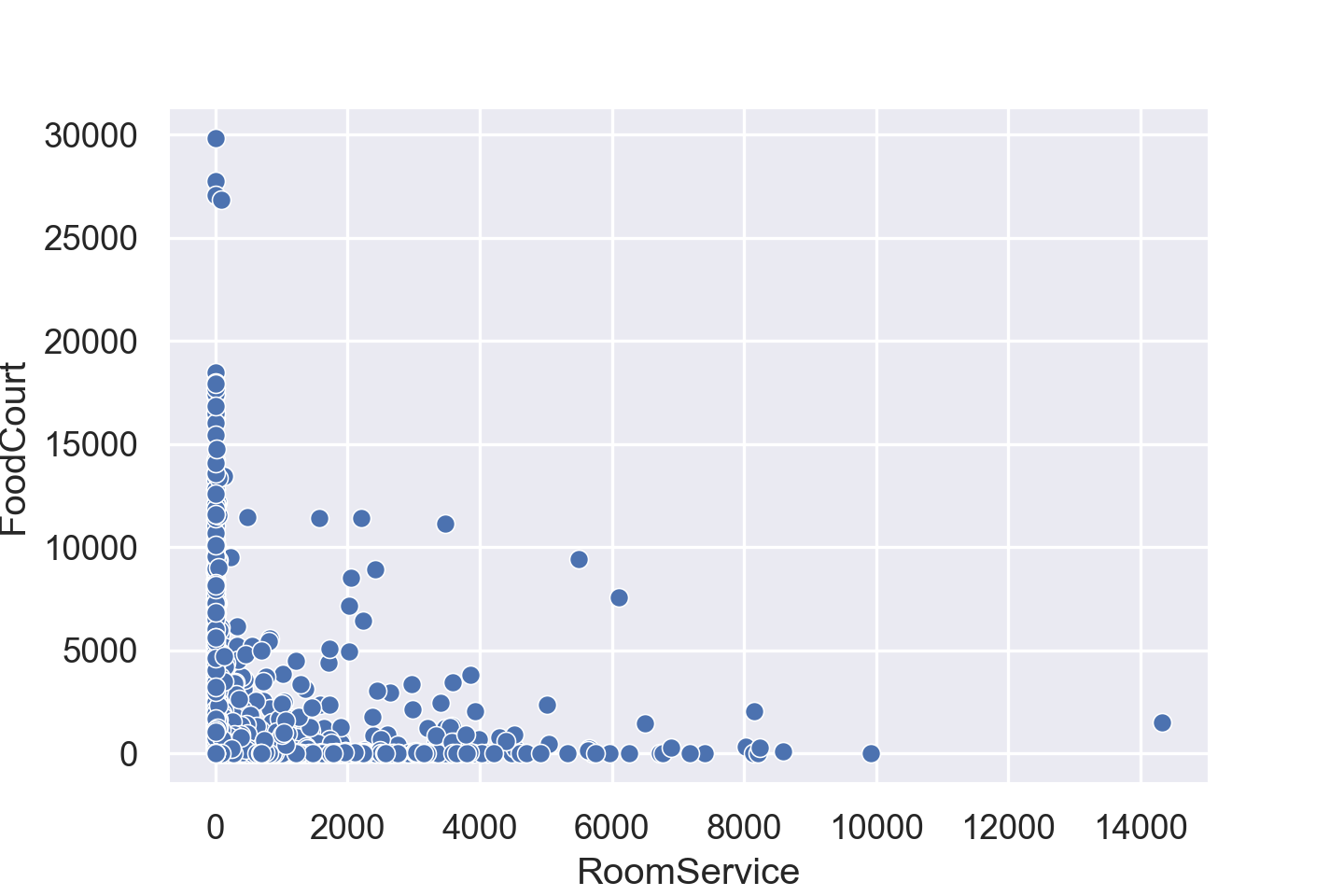
从图中似乎没有明显的相关关系,但对于大部分人,某一项消费高的人,另外一项消费就会很少。
散点图通过对点的形状、大小或者点的颜色的不同,可以引入第三个分类变量。
sns.scatterplot(data=train_data, x="RoomService", y="FoodCourt", hue="Transported")
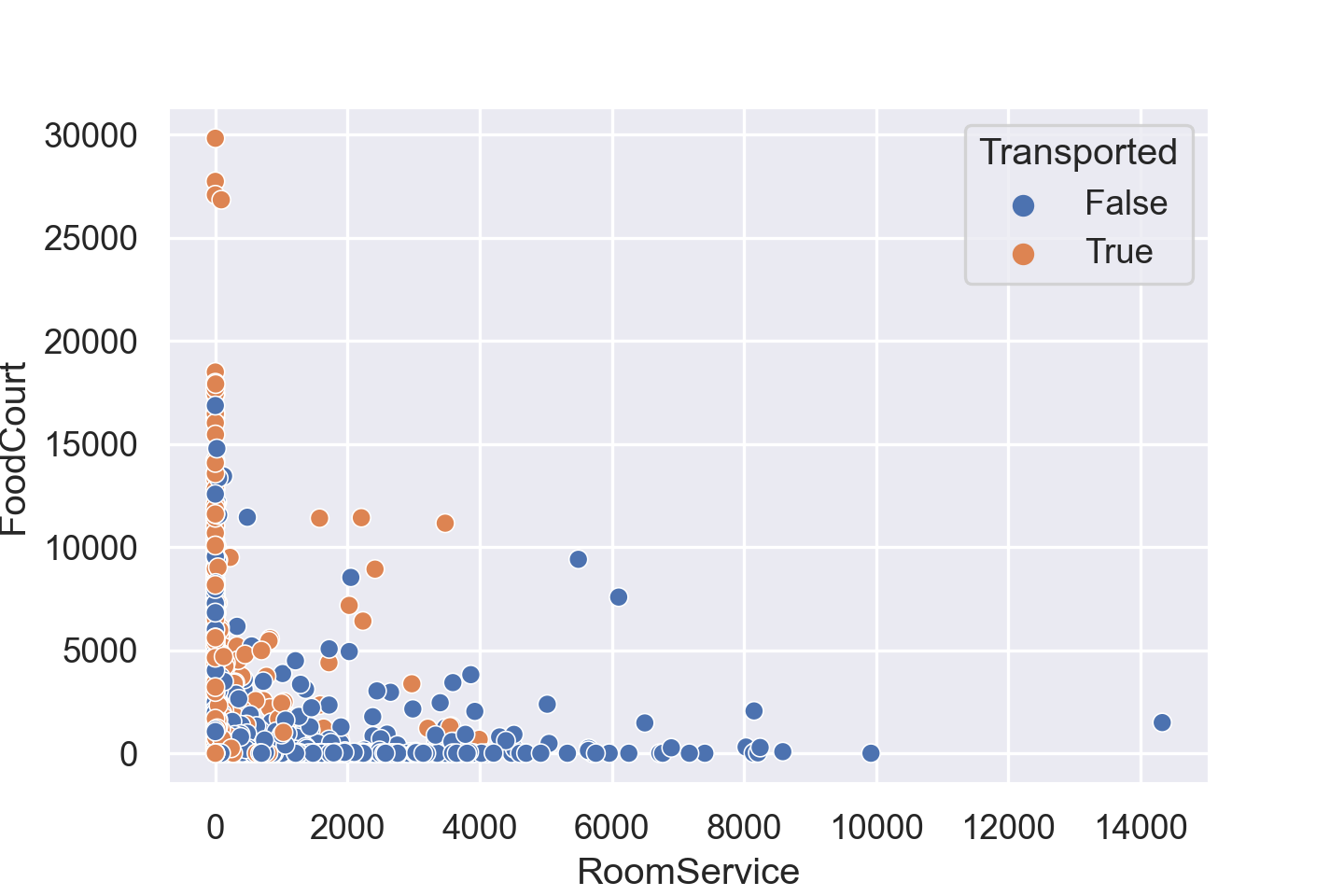
可以看出,RoomService 消费高的几乎都没有被传送。这也可以从直方图中得到印证。
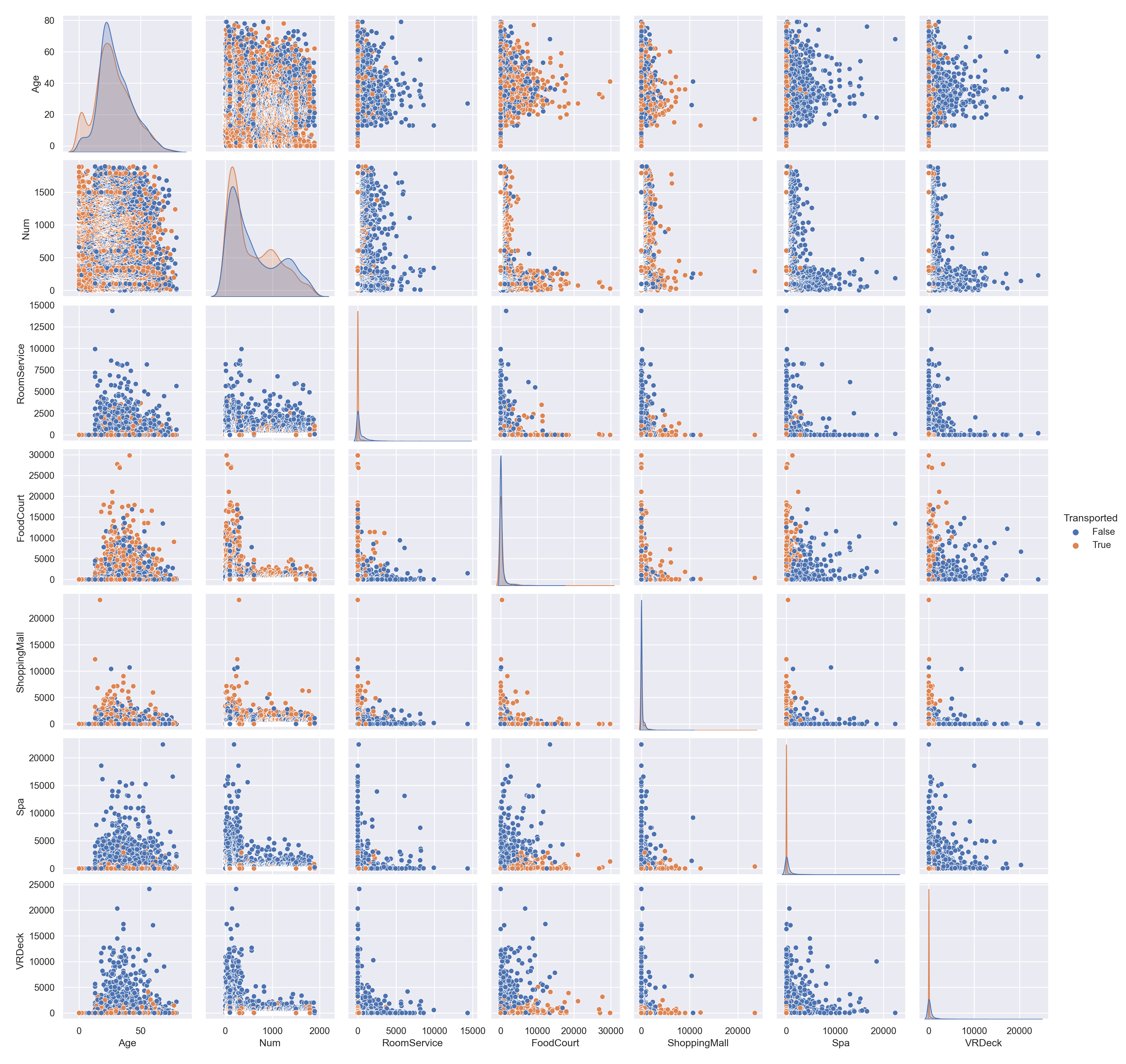
最后,对两两变量之间绘制散点图,seaborn 中可以通过 pairplot 来实现。
sns.pairplot(train_data[['Age', 'Num', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck', "Transported"]], hue="Transported")
4.5 热力图
热力图是将矩阵数据绘制成颜色编码的矩阵,通过颜色的不同体现值的高低。
在 EDA 中,通常用热力图来绘制不同变量之间的相关系数。
相关系数是由皮尔逊提出的统计指标,反映了变量之间相关关系的密切程度。它是两个变量的协方差与其标准差的乘积之比,本质上是协方差的归一化测量。
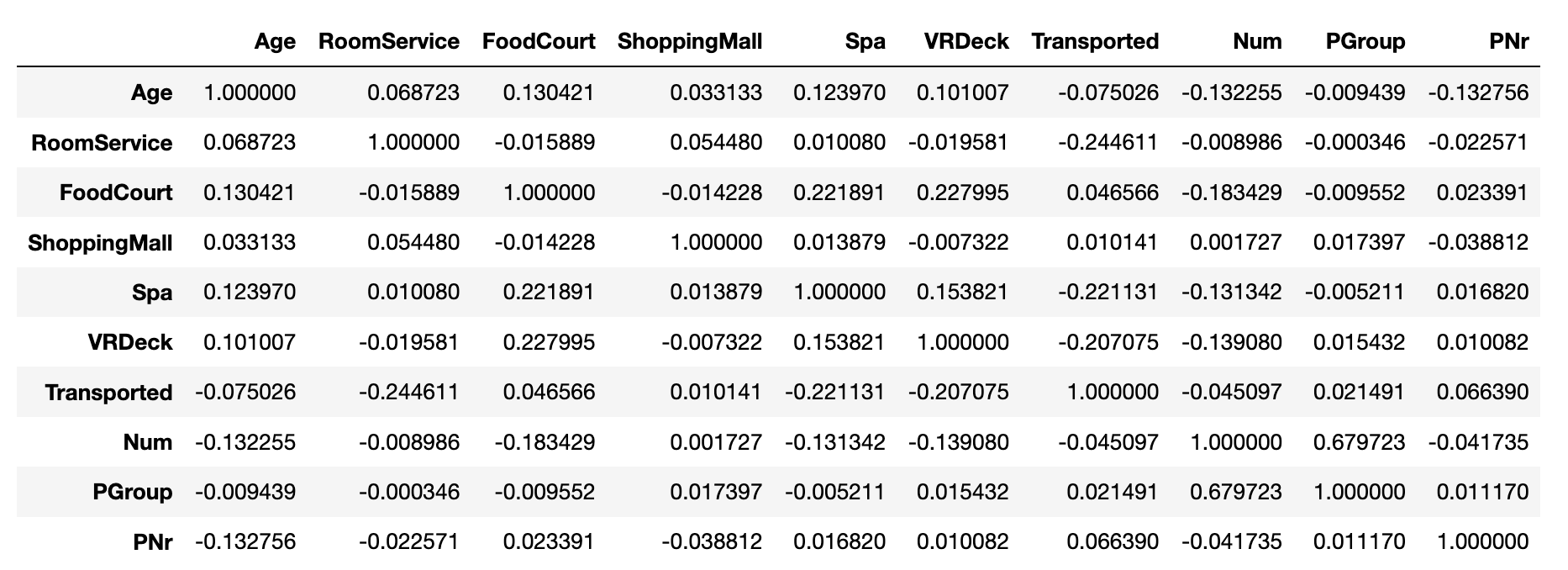
通过 DataFame 的 corr 方法可以很容易的计算。
train_data.corr()
将上述矩阵数据绘制成热力图,
plt.figure(figsize=(15,18))
sns.heatmap(train_data.corr(), annot=True)
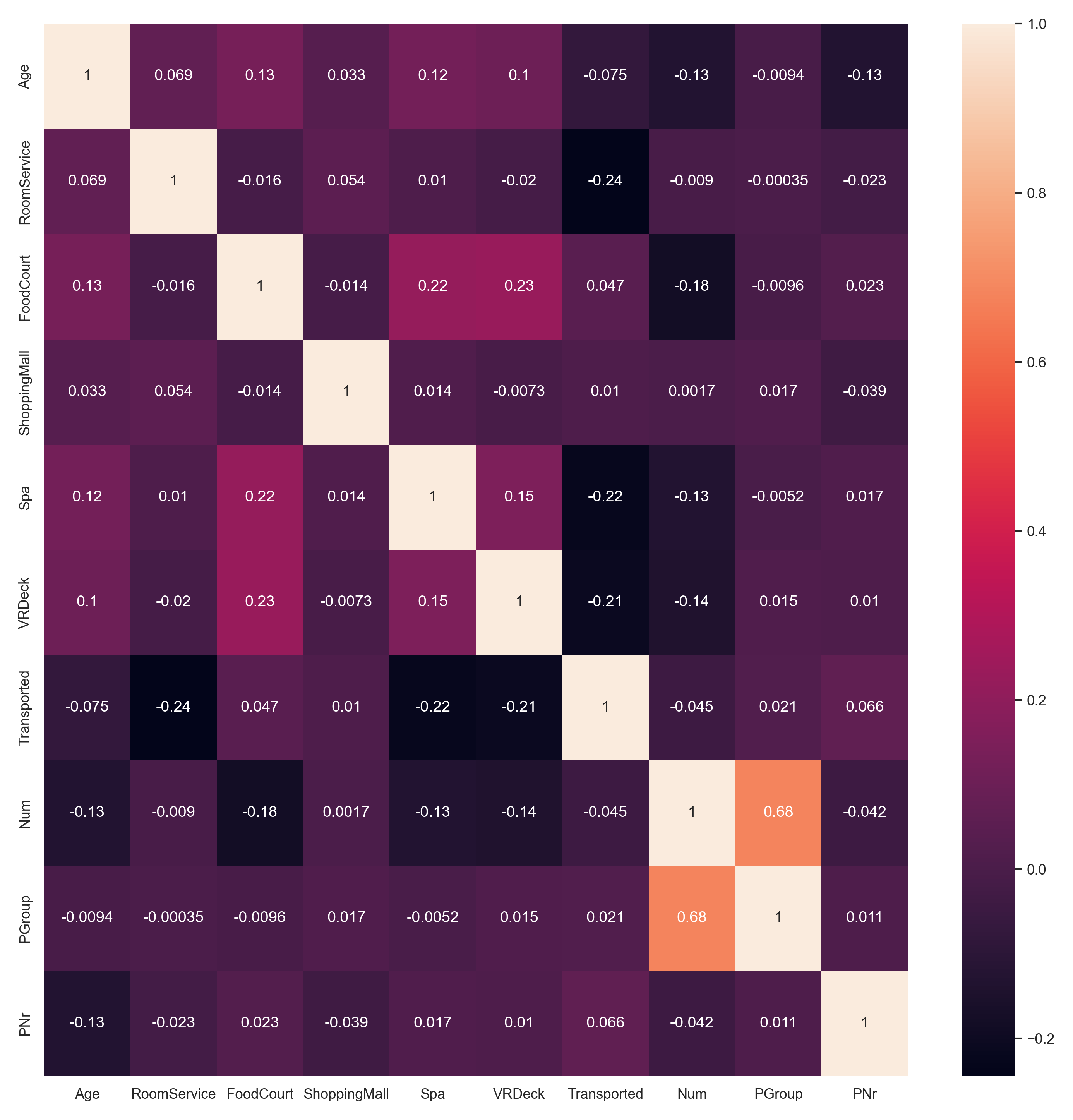
可以看出 Group 序号和 Num 序号相关性是最大的。
5. 数据预处理
数据处理主要分为特征选择、缺失值处理、特征编码、归一化、降维等等
5.1 缺失值
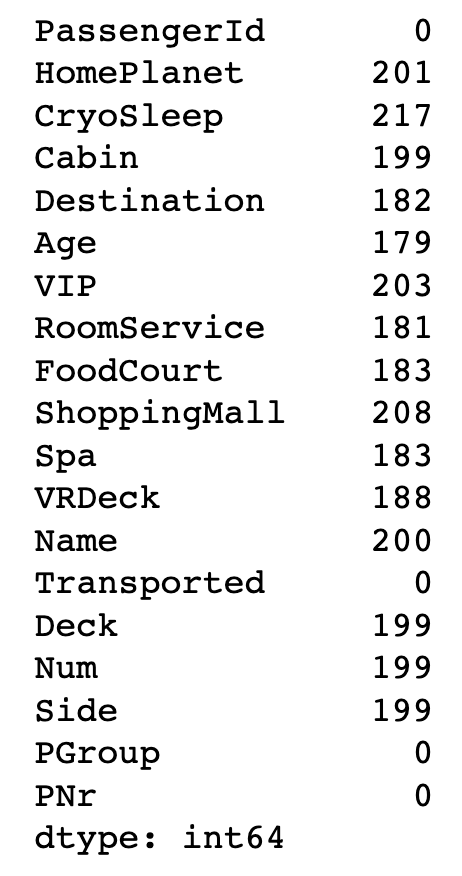
首先查看一下数据缺失情况
train_data.isnull().sum()
再看一下数据的类型。
train_data.info()

object 属于分类变量,它的值都是离散的;float 则属于连续变量,它的值都是连续的。
1. 简单策略
对于连续值的处理,主要是使用平均值或者中位数进行填充;而对于离散值则是使用众数进行填充,也就是出现最多的类别值。
通过 pandas 和 sklearn 的内置方法都可以实现。
pandas 方法,首先通过 select_dtypes 选择指定的数据列,然后通过 fillna 进行缺失值填充。
df = train_data.copy()
df_numeric = df.select_dtypes(include = np.number)
df_categorical = df.select_dtypes(include = object)
for col in df_numeric.columns:
df[col] = df[col].fillna(value = df[col].mean())
for col in df_categorical.columns:
df[col] = df[col].fillna(value = df[col].mode()[0])
sklearn 方法,sklearn 的方法相对麻烦一点,需要实例化 imputer,通过 fit 去拟合数据,然后用 transform 对数据进行缺失值填充,同时返回的是填充后的数组,最后还需要转换成 DataFrame,拼接之后就可以了。
from sklearn.impute import SimpleImputer
start = time.time()
df_numeric = df.select_dtypes(include = np.number)
df_categorical = df.select_dtypes(include = object)
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(df_numeric)
values = imputer.transform(df_numeric)
df_numeric = pd.DataFrame(values, columns = df_numeric.columns)
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer.fit(df_categorical)
values = imputer.transform(df_categorical)
df_categorical = pd.DataFrame(values, columns = df_categorical.columns)
df_sklearn = pd.concat([df_numeric, df_categorical], axis = 1)
最后看一下数据,可以看出来结果是一样的。
train_data[train_data.isnull().T.any()].select_dtypes(include = np.number).head(10)
df[train_data.isnull().T.any()].select_dtypes(include = np.number).head(10)
df_numeric[train_data.isnull().T.any()].head(10)
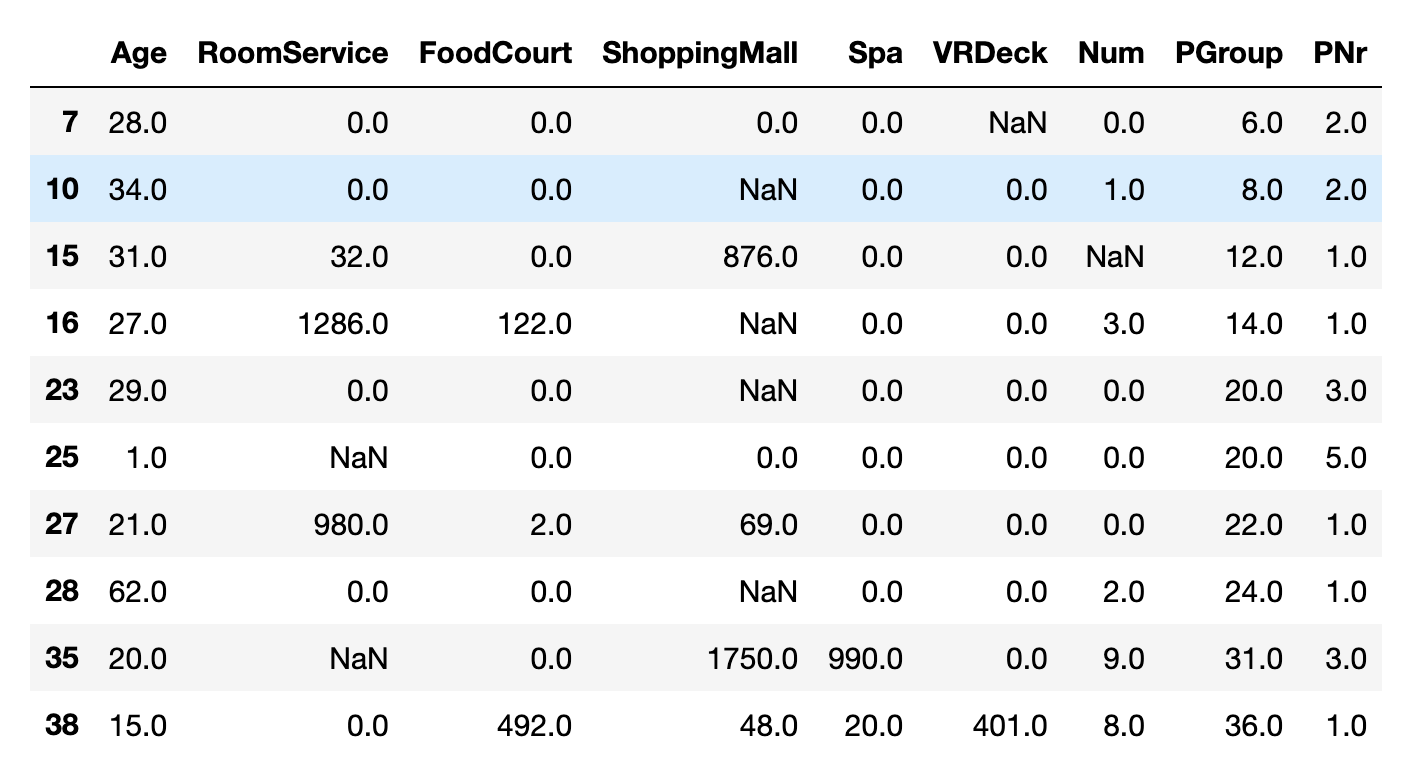
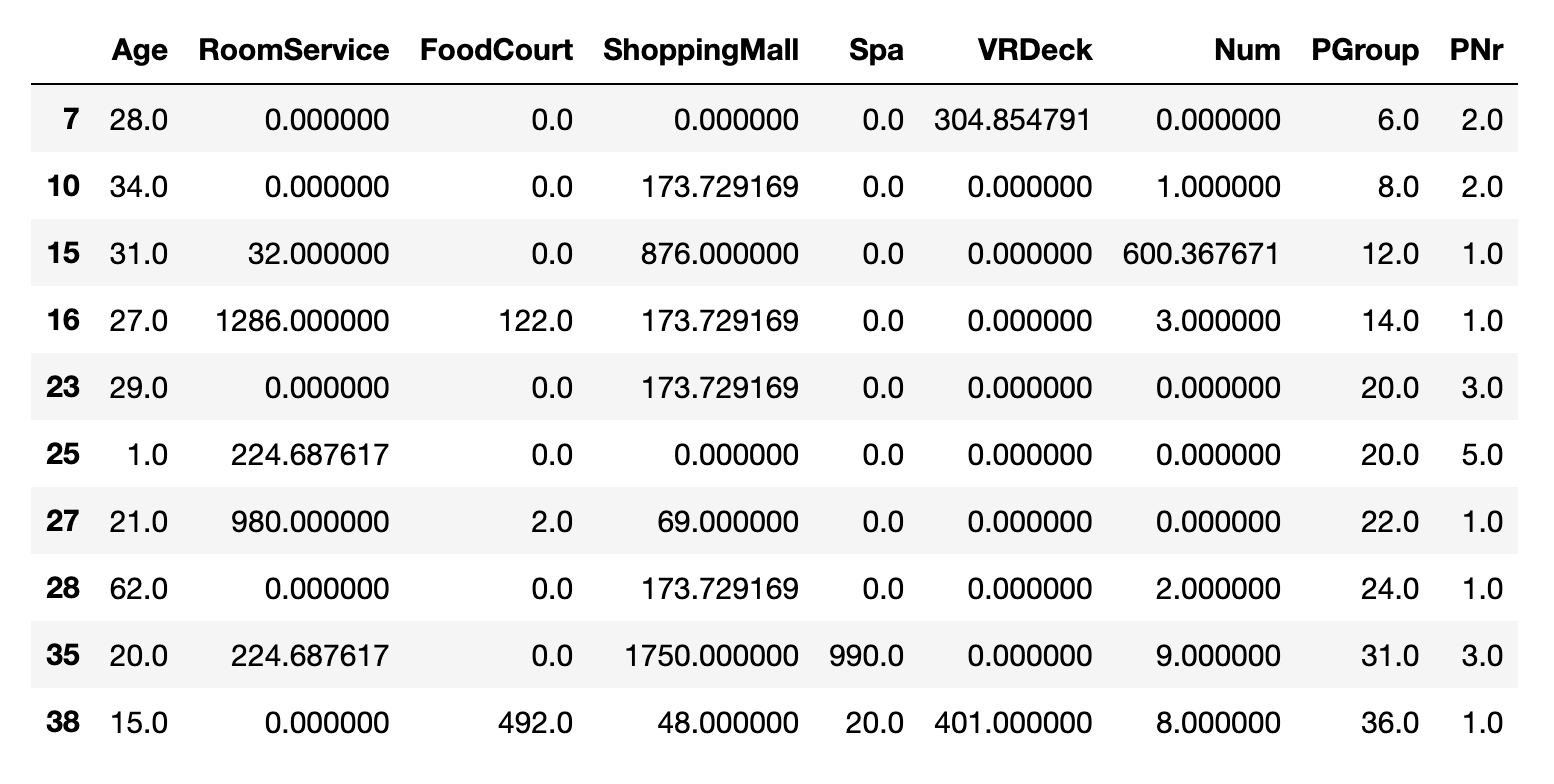
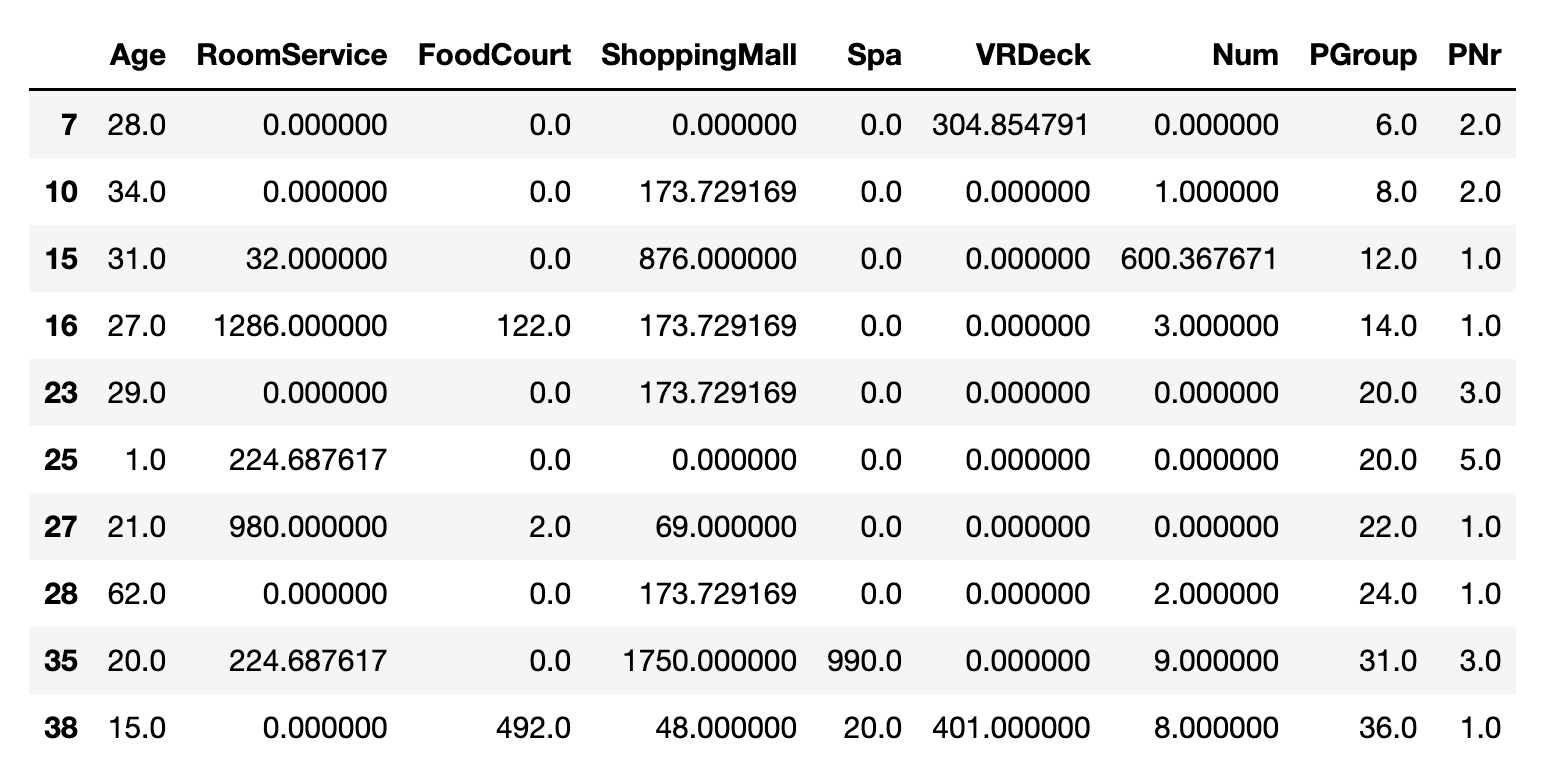
2. KNN 策略[2]
用简单策略的单变量方法可能无法准确的填补缺失值,例如某段道路的空气污染情况缺失,但是已知其车辆密度和或其他与空气质量相关的特征,利用空气污染情况的平均值或者中无数去填补就不是一个好的策略。更好的方法是,通过其他特征去找一个最相似的也就是最近邻的一个或多个样本,利用该样本的平均值去填补缺失的情况。
具体方法是,每个样本的缺失值使用来自训练集中找到的 n_neighbors 个最近邻的平均值进行估算。如果两个样本都没有缺失的特征是接近的,那么两个样本是接近的。
KNN 插补只能用在数值型变量中,如果是分类变量则需要 one-hot 后才能使用。
from sklearn.impute import KNNImputer
x = [[1, np.nan, 5], [1, 0, 0], [3, 3, 3]]
imputer = KNNImputer(n_neighbors = 1)
print(imputer.fit_transform(x))
imputer = KNNImputer(n_neighbors = 2)
print(imputer.fit_transform(x))
y = [[1, np.nan, 5], [1, 0, np.nan], [3, 3, 3]]
imputer = KNNImputer(n_neighbors = 1)
print(imputer.fit_transform(y))

数据集 x 有三个样本,距离第一个样本最近的是样本3,因此填充值是3。当 n_neighbors = 2 时,填充值则是另外两个样本该特征的平均值。
最后观察一下用 KNN 插补后的结果
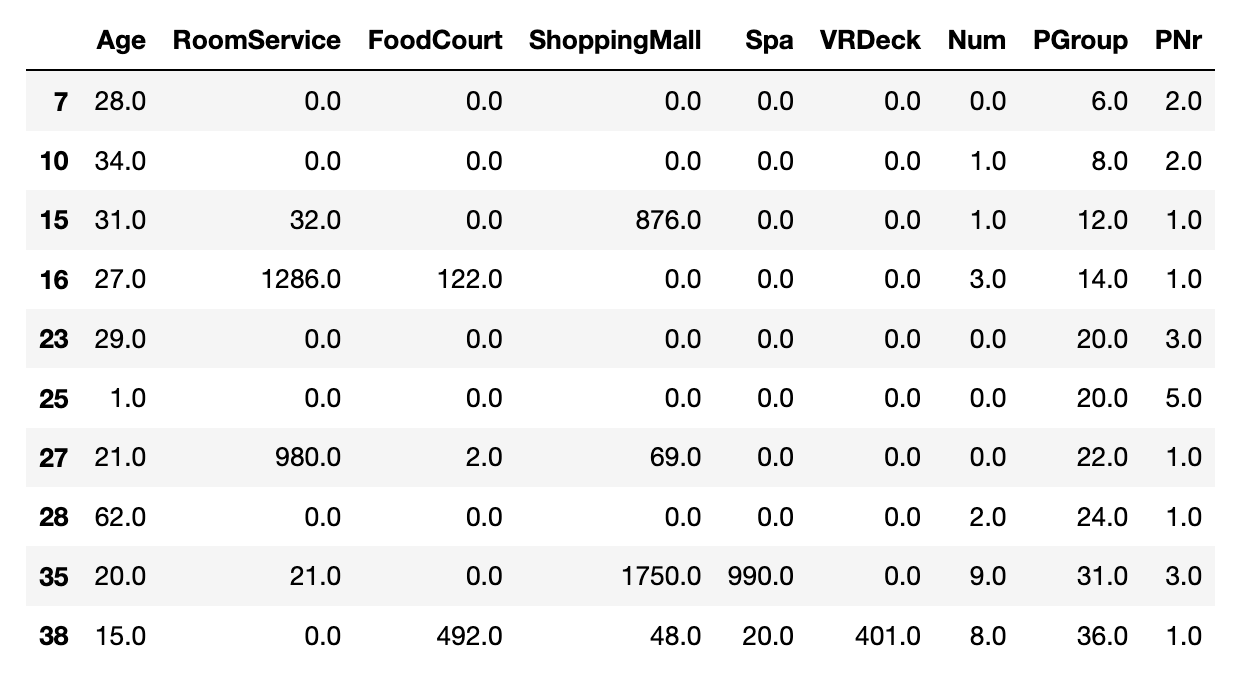
可以看出来比平均值填补要合理的多,毕竟,年龄是1岁的人,情理上讲是不会有消费的。
5.2 特征编码
编码过程主要是将离散的数值或字符串映射到连续的整数空间。
在分类问题中,首先要对标签值进行编码。
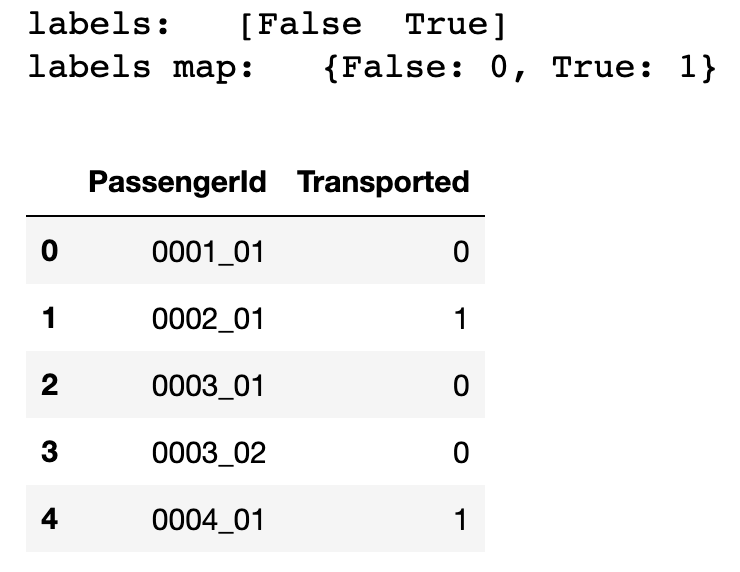
通过 pandas 进行编码,需要用 unique 得到分类值,然后用 map 进行映射。
df = train_data.copy()
labels = df['Transported'].unique()
print('labels: ', labels)
print('labels map: ', dict(zip(labels, range(len(labels)))))
df['Transported'] = df['Transported'].map(dict(zip(labels, range(len(labels)))))
df[['PassengerId', 'Transported']].head()
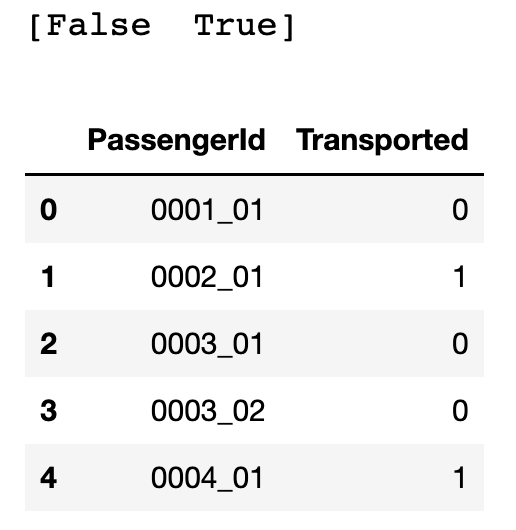
sklearn 中的 LabelEncoder 同样可以实现上述操作。
from sklearn.preprocessing import LabelEncoder
df = train_data.copy()
le = LabelEncoder()
df['Transported'] = le.fit_transform(df['Transported'])
print(le.classes_)
df[['PassengerId', 'Transported']].head()
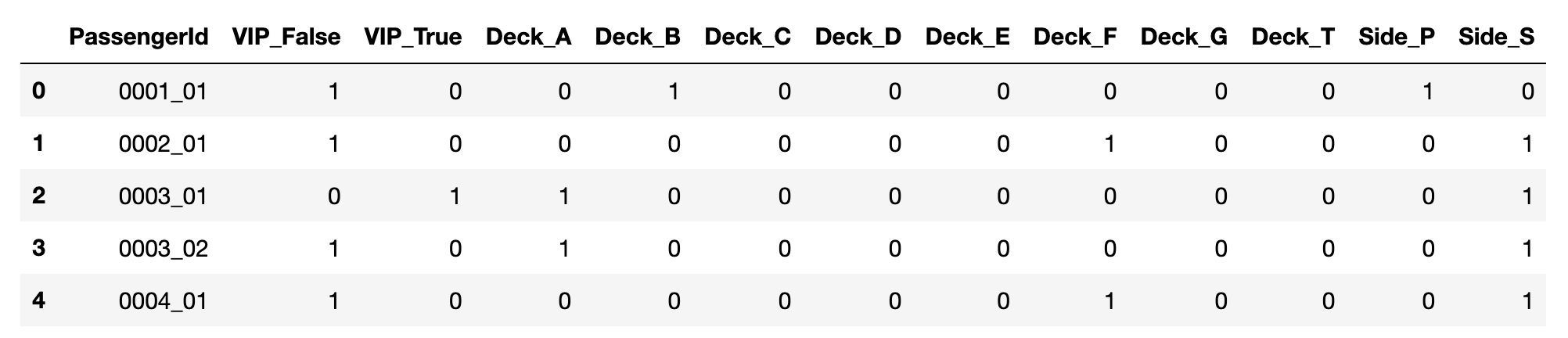
在对特征值进行编码的时候,不仅仅要映射到整数空间,还需要进行 ont hot 编码。
pandas 中可以使用 get_dummies 方法。
df = train_data.copy()
df = pd.get_dummies(df, columns=['HomePlanet', 'CryoSleep', 'Destination', 'VIP', 'Deck', 'Side'])
部分变量转换结果如下。
sklearn 中需要使用 OneHotEncoder,返回的是一个数组,需要另外取出列名后再生成 DataFrame。
from sklearn.preprocessing import OneHotEncoder
df = train_data[['HomePlanet', 'CryoSleep', 'Destination', 'VIP', 'Deck', 'Side']].copy()
encoder = OneHotEncoder(handle_unknown='ignore')
encoder.fit(df)
print(encoder.categories_)
values = encoder.transform(df).toarray()
print(encoder.get_feature_names_out())
pd.DataFrame(values, columns = encoder.get_feature_names_out())
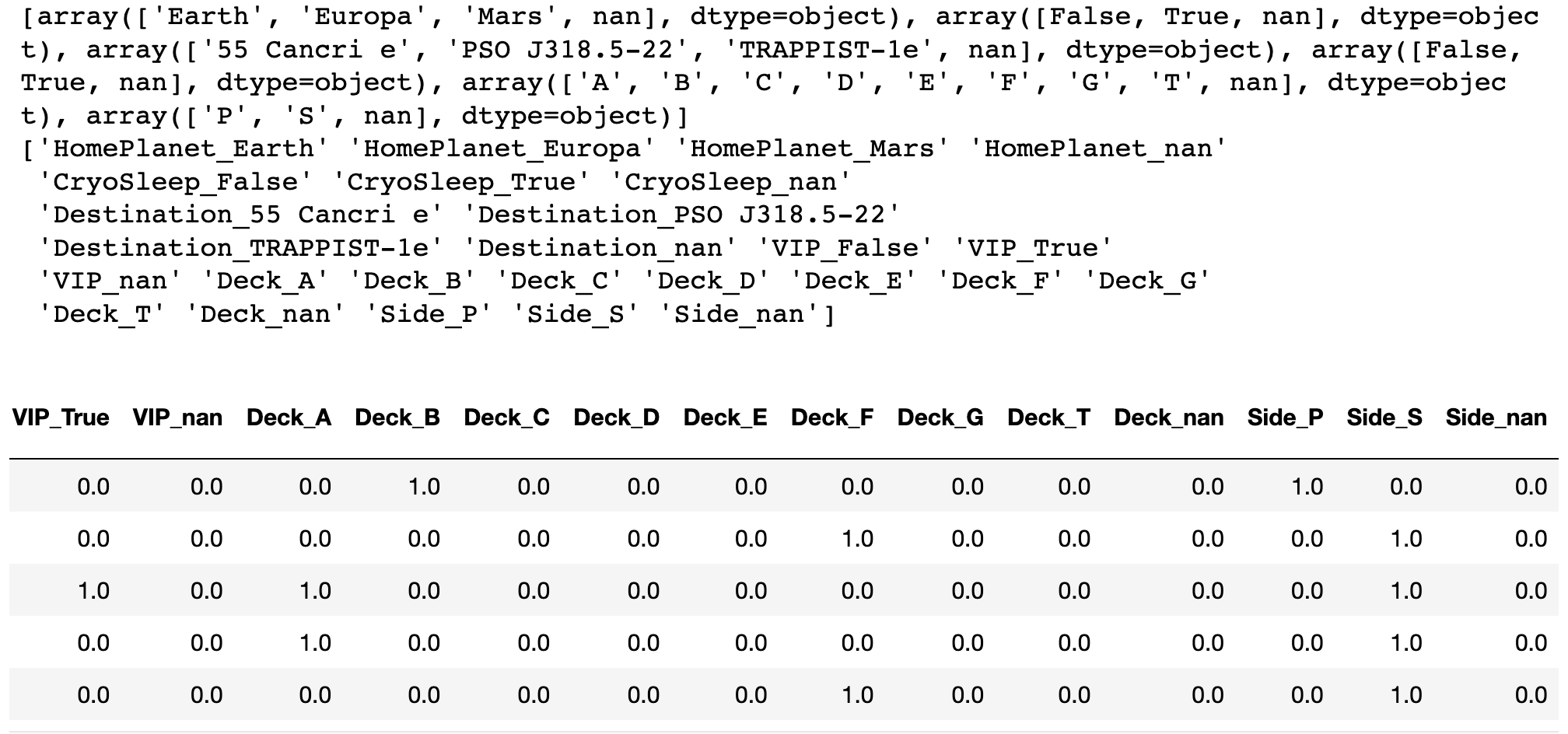
可以看出 OneHotEncoder 默认对 NaN 值也进行编码的,会单独生成一列,而 get_dummies 默认则不会,可以通过传参使它们的结果相同。
one hot 编码也可以少输出一列,例如一个变量有三个类别,可以使用两个变量去表示,当属于第三个类别时,这两个变量的值都为0,在以上两个接口中都有相应参数进行设置。
5.3 标准化和归一化
在标准化之前,在以上操作的基础上,先把不需要的列去掉。
df.drop(['PassengerId', 'Cabin', 'Name'], axis = 1, inplace = True)
1. 正态化
如前所述,对于金额类的类别由于方差过大、异常值过多,需要进行对数处理。
对于哪些类别需要进行对数处理,一是通过之前的箱线图看哪些异常值过多然后进行处理,二是分别计算每个类别的偏度,超过阈值则进行处理。
事实上,右偏的数据可以进行取对数、平方根、三次方根等等方式进行正态化处理,这些函数随着自变量的增大逐渐变缓,左偏的则需要进行指数计算。
偏度[3]的计算公式为
首先查看一下各列的偏度值
df.skew()
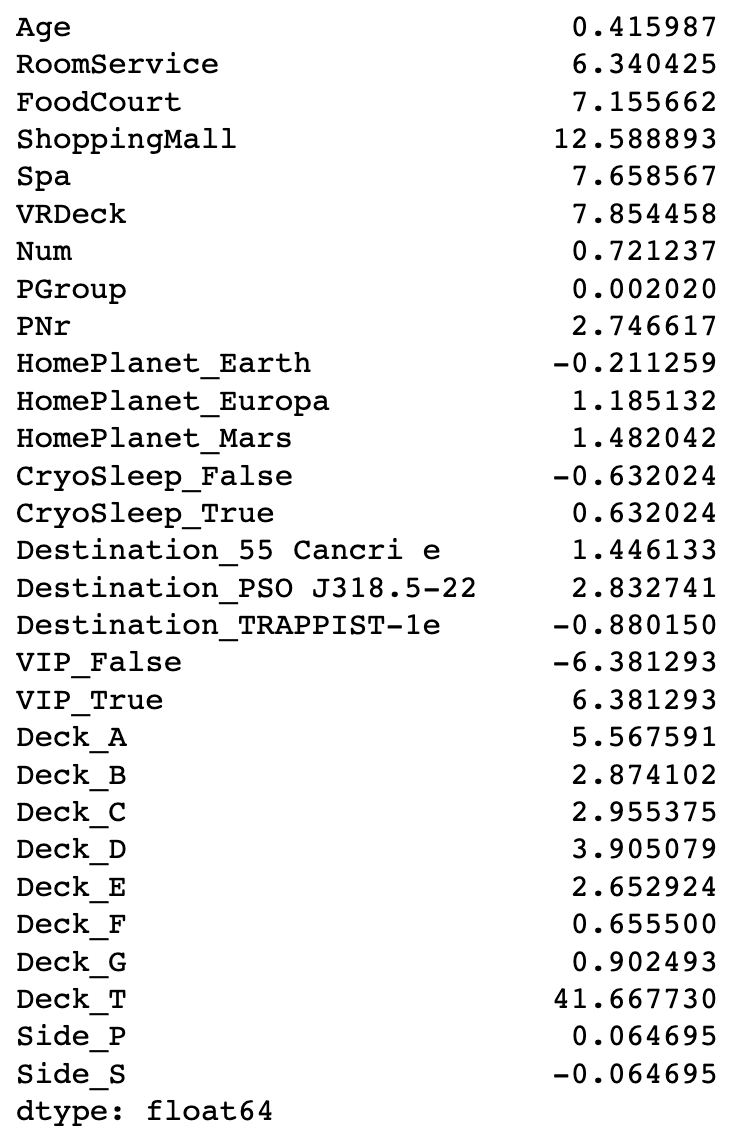
只对数值型的变量进行处理,通过 numpy 的 log1p 方法进行取对数,log1p 自动将输入加 1 后取对数,避免了 0 值报错的情况。
for column in ['Age', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck', 'Num', 'PGroup', 'PNr']:
skew = df[column].skew()
if skew >= 0.5:
df[column] = np.log1p(df[column])
在 sklearn 中有更专业的方法对数据进行正态化处理,分别为 Box-Cox[4] 和 Yeo–Johnson 变换。
Box-Cox 变换形式如下
式中,$\lambda$ 的值不用直接给出,是通过最大似然估计,判定不同的 $\lambda$ 的值的情况下,哪一个得到的结果更符合正态分布。从公式中可以看出,Box-Cox 要求 $y$ 的值严格为正。
Yeo–Johnson 变换则为
Yeo–Johnson 变换支持 $y$ 为 0 或负,解决方法也正是取值加 1。
在 sklearn 中,以上两种变换都通过 PowerTransformer[5] 实现。变换后默认标准化数据,可以通过 standardize = False 关闭。
df_tmp = df[['Age', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck', 'Num', 'PGroup', 'PNr']].copy()
pt = PowerTransformer('yeo-johnson', standardize = False)
pt.fit(df_tmp)
values = pt.transform(df_tmp)
df_lambdas = pd.Series(pt.lambdas_, index = df_tmp.columns)
df_power = pd.DataFrame(values, columns = df_tmp.columns).head()
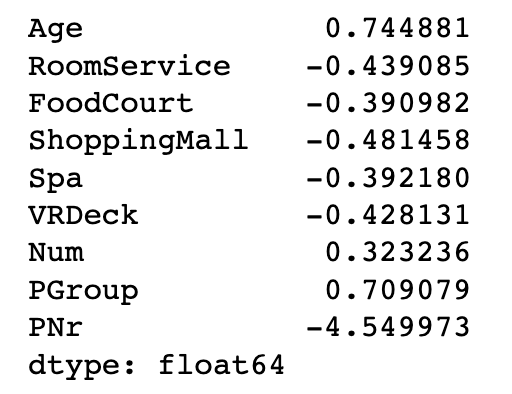
lambdas_ 属性显示最优的 lambdas 值,变换的结果也是根据这个值。看一下每列的 lambdas 值为
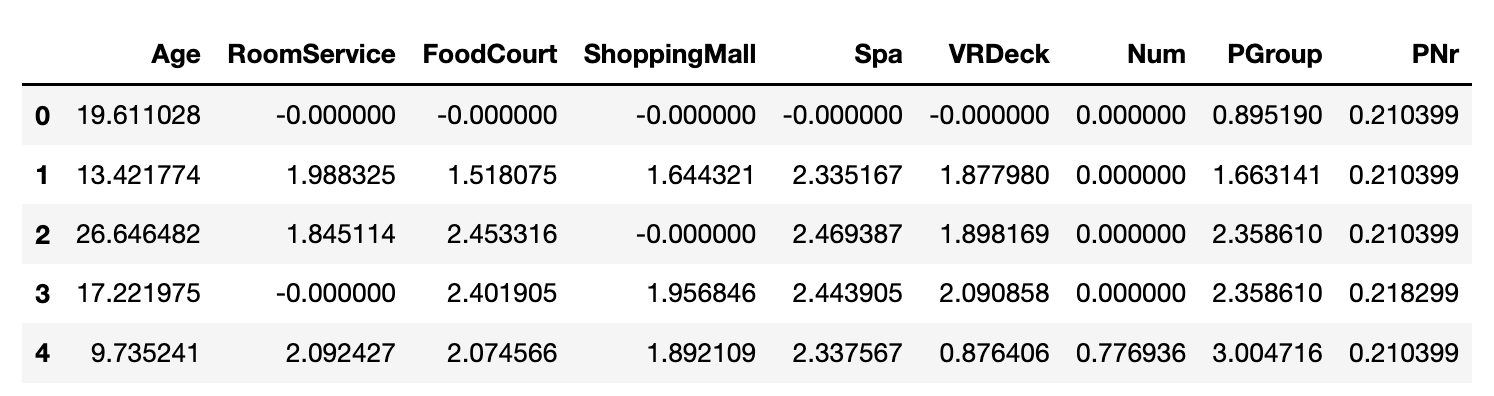
转换后的结果为,这里没有进行标准化。
最后再画图看一下变换前和变换后的数据分布
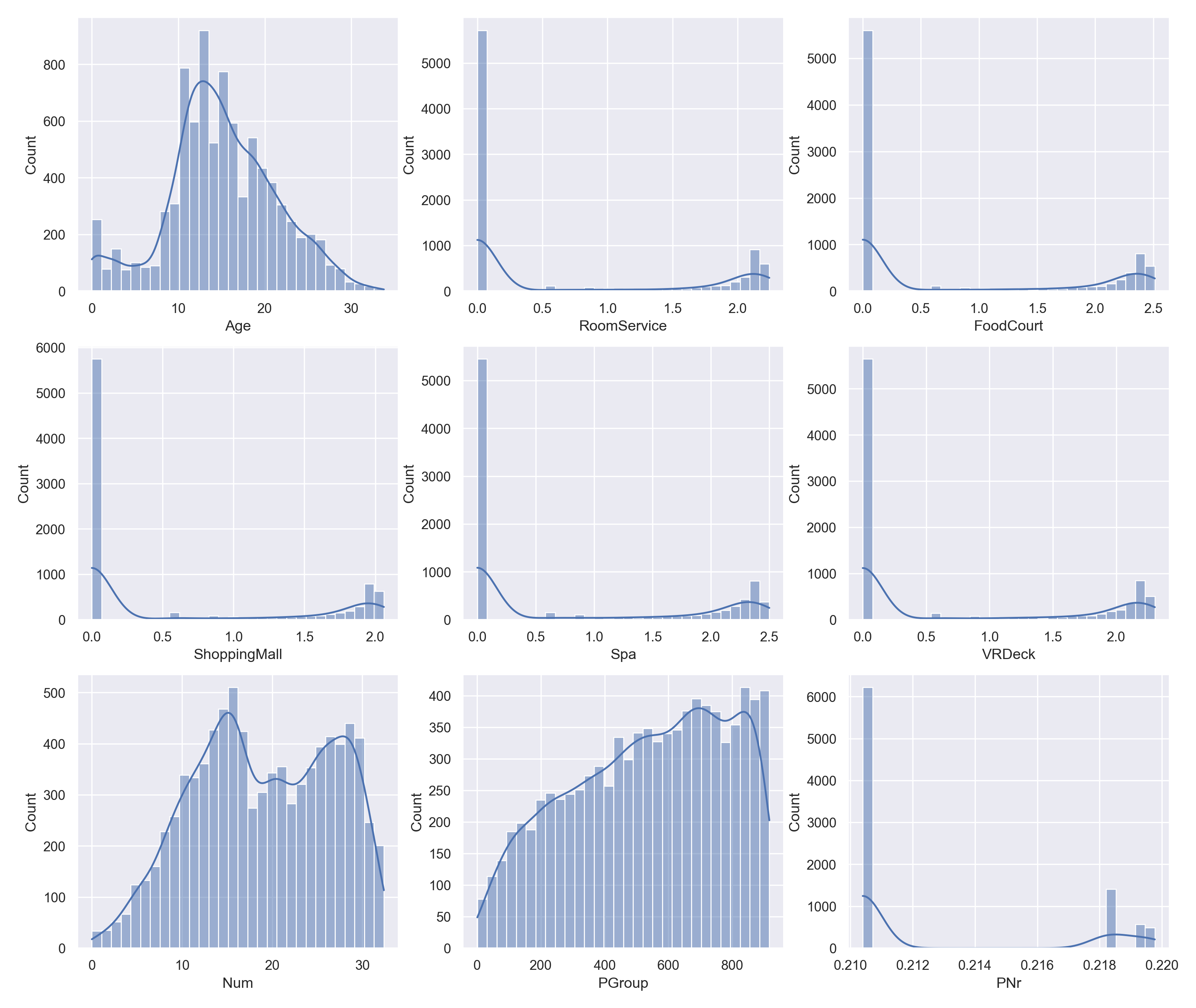
感觉变换后也不是特别正态分布。
再看一下变换前后的箱线图
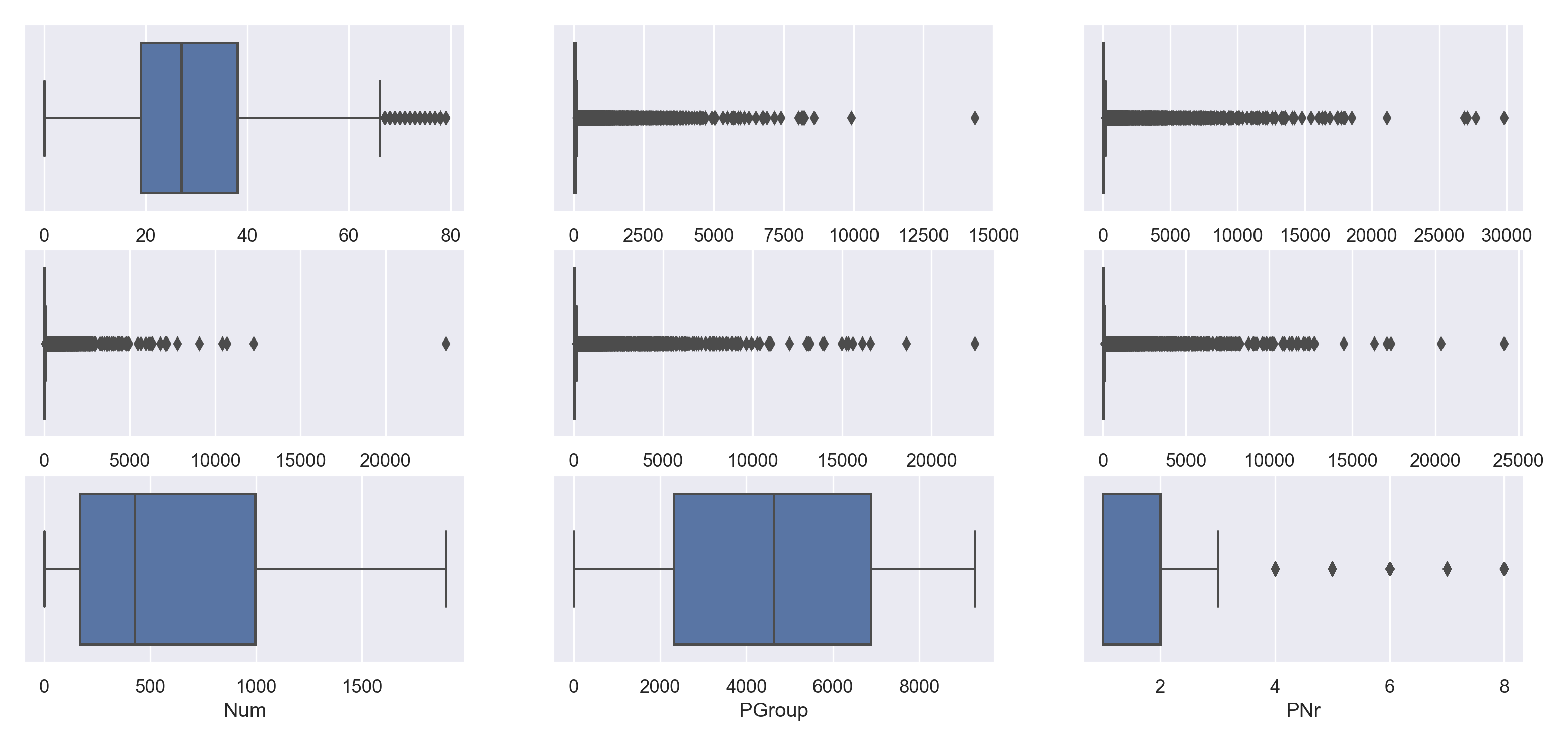
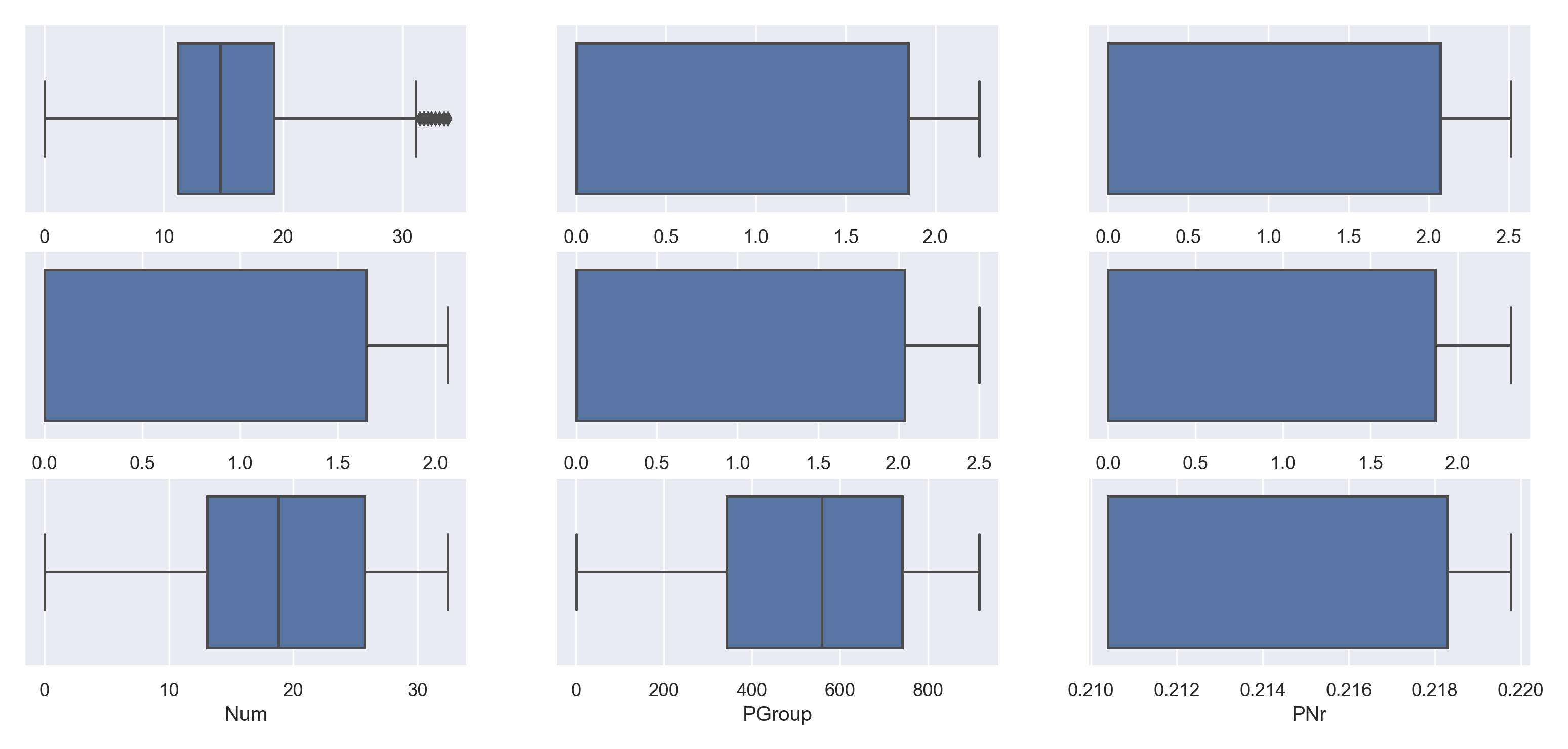
可以发现异常值减少了许多。
2. 标准化
上面的正态化属于非线性变换,而标准化和归一化就属于线性变换了,只是统一量纲不会改变数据的分布类型。
标准化[6]通过均值去除和方差缩放来对样本进行统一标准。
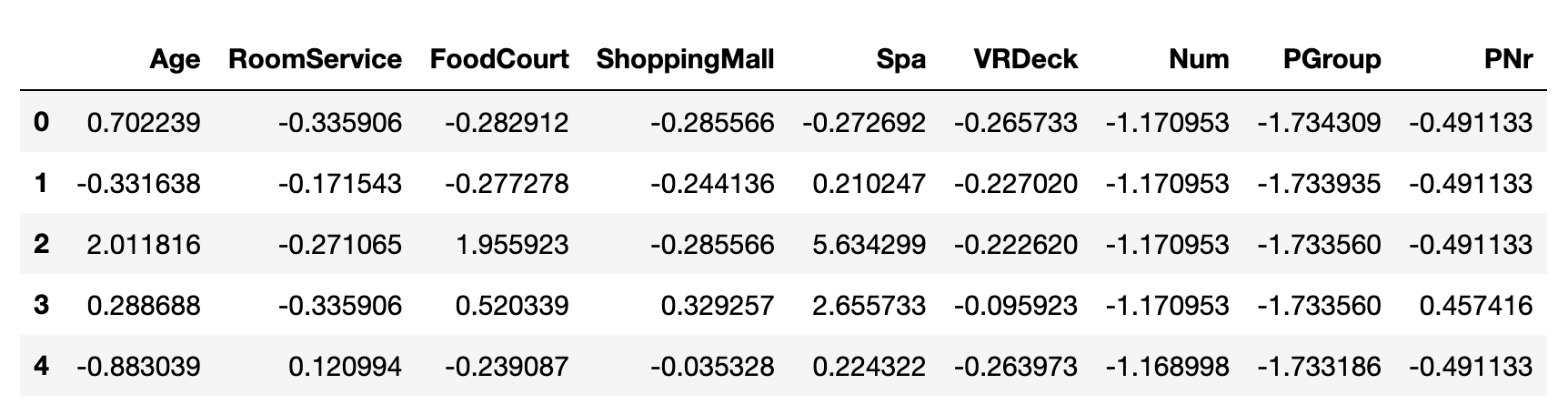
pandas 中有广播机制,因此利用下式即可计算出结果。
(df_tmp - df_tmp.mean()) / df_tmp.std()
计算结果为
sklearn 方法
(df_tmp - df_tmp.mean()) / df_tmp.std()
计算结果为
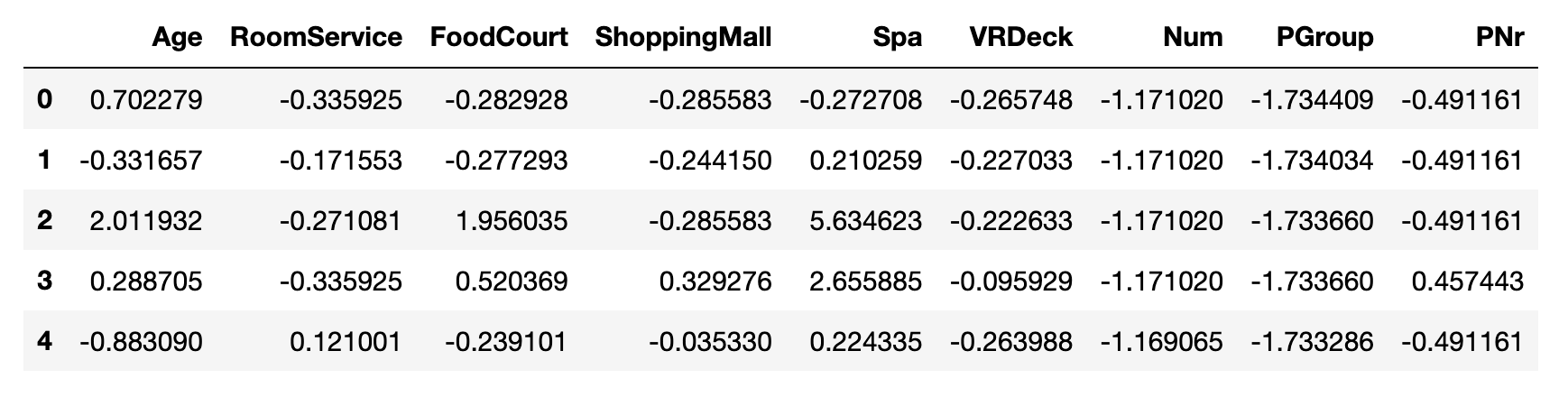
结果有一点不同,可能是 pandas 使用的是样本方差,方差结果乘以了 $\frac{n}{n - 1}$
我们调整一下自由度的值
(df_tmp - df_tmp.mean()) / df_tmp.std(ddof = 0)
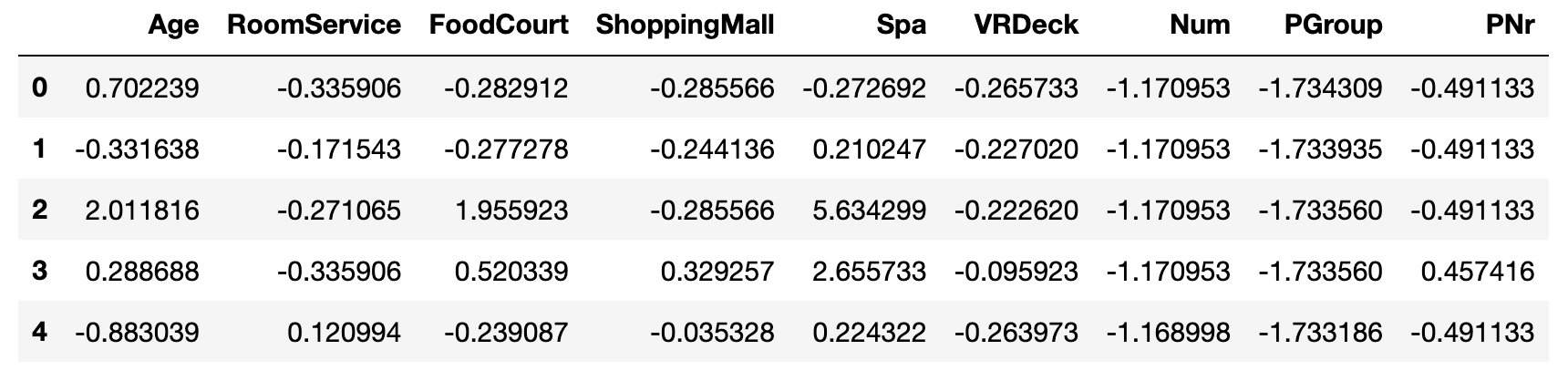
果然结果一样了。
3. 归一化
归一化是将数据线性映射到 $[0,1]$ 区间,使用的是数据中最大与最小值。
pandas 方法
(df_tmp - df_tmp.min()) / (df_tmp.max() - df_tmp.min())
计算结果为
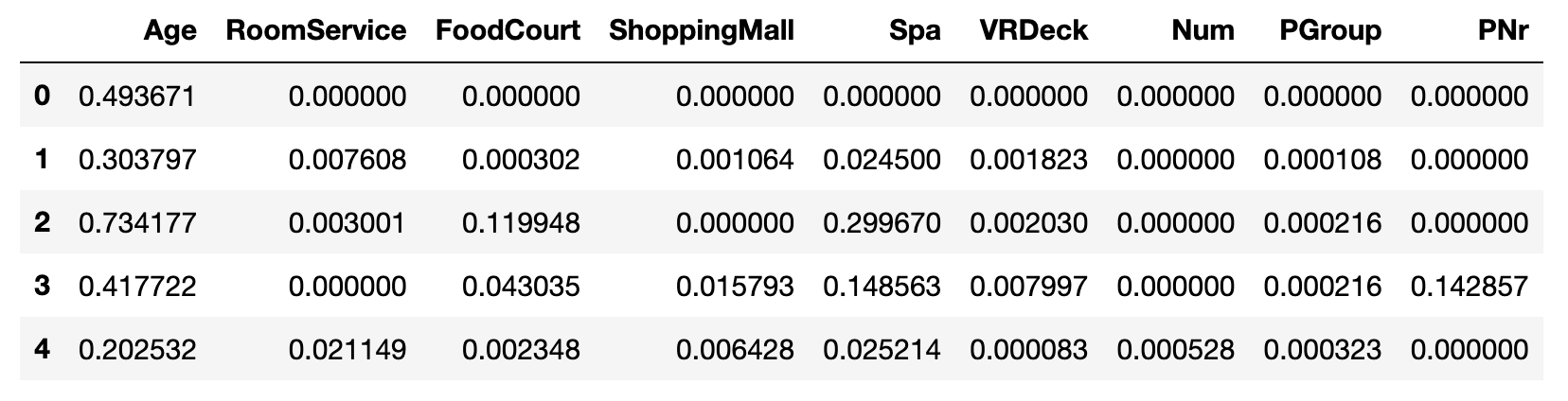
sklearn 方法
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df_tmp)
print(scaler.data_min_)
print(scaler.data_max_)
values = scaler.transform(df_tmp)
df_scaler = pd.DataFrame(values, columns = df_tmp.columns)
df_scaler.head()
计算结果为
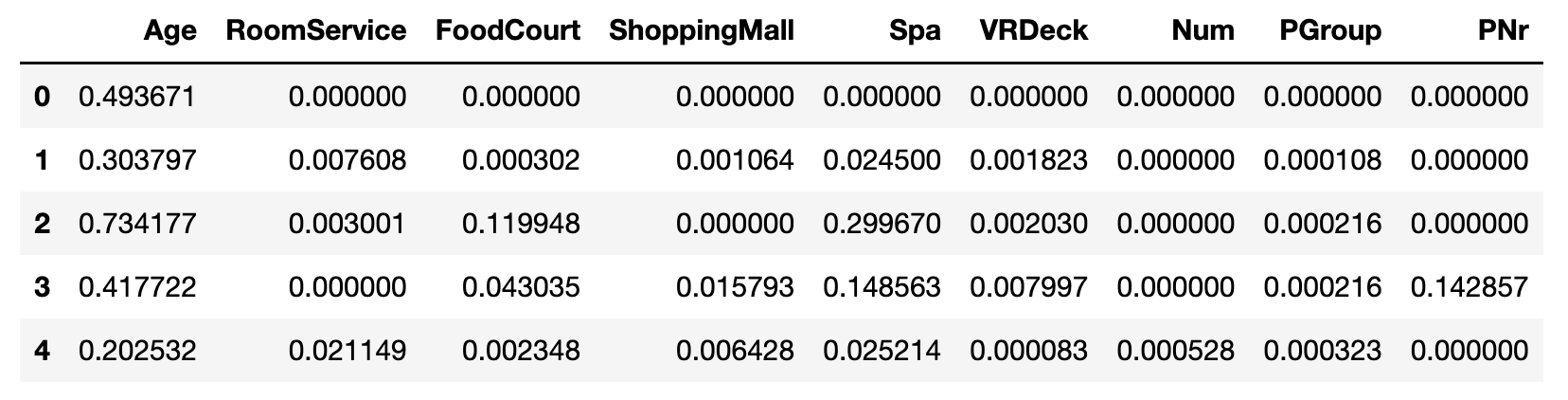
参考
1. 机器学习笔记 - 探索性数据分析(EDA) 概念理解 - csdn
2. KNNImputer: A robust way to impute missing values (using Scikit-Learn)
3. Python统计学(五)——切比雪夫、偏度及峰度 - zhihu
4. box-cox变换
5. Power transform - wiki
6. 标准化和归一化 - csdn
7. 样本分布不正态?
8. A Comprehensive Guide to Data Exploration
9. 什么是核密度估计?如何感性认识? - zhihu